
.svg)

Sommaire
L' aperçu
Amazon Textract a popularisé l'OCR basé sur le cloud (Reconnaissance Optique de Caractères: la technologie fondamentale utilisée pour lire le texte des images). Cependant, le traitement de mises en page de documents chaotiques, comme des tableaux de factures profondément imbriqués, via une API cloud héritée, introduit de sérieuses frictions. Vous envoyez une image au cloud et vous vous noyez ensuite dans des milliers de lignes de code de validation personnalisé pour rendre le JSON structuré (JavaScript Object Notation : le format standard léger d'échange de données) utilisable.
Le passage à l'échelle du traitement des documents exige une solution qui équilibre une précision chirurgicale, une intégration conviviale pour les développeurs et des coûts prévisibles. Nous allons détailler les principales alternatives à Textract pour vous aider à choisir l'outil optimal pour votre stack technologique.
Évaluer les meilleurs concurrents d'Amazon Textract pour votre stack tech
Google Document AI, Azure Document Intelligence, et les plateformes d'API spécialisées offrent des avantages architecturaux distincts par rapport à Textract. En fin de compte, votre choix dépend strictement de la priorité de votre organisation : consolidation des fournisseurs ou extraction de données agile.
Lorsque les responsables de l'ingénierie évaluent les fournisseurs de services cloud, l'architecture dicte la décision, car la migration entre des écosystèmes massifs résout rarement les goulots d'étranglement d'extraction sous-jacents.
Azure Document Intelligence
Microsoft applique une conformité d'entreprise robuste et fournit des données JSON hautement structurées. Il excelle dans les environnements strictement réglementés. Cependant, la formation de modèles personnalisés s'avère rigide face à des documents fournisseurs très variables, nécessitant une surcharge importante pour la maintenance à mesure que les mises en page évoluent.
Avantages :
- Modèles pré-entraînés leaders du secteur : Azure propose des modèles fantastiques, prêts à l'emploi, pour les factures, les reçus, les cartes d'assurance maladie, les formulaires W-2 et les documents d'identité.
- Modèles de documents neuronaux personnalisés : L'interface utilisateur pour l'étiquetage et l'entraînement de vos propres modèles d'extraction personnalisés est très soignée et nécessite relativement peu d'échantillons pour obtenir de bons résultats.
- Écriture manuscrite : Gestion exceptionnelle de l'écriture manuscrite désordonnée et cursive.
Inconvénients :
- Verrouillage de l'écosystème : Les meilleures fonctionnalités nécessitent souvent une intégration profonde avec Azure Cognitive Services ou Power Automate.
- Coût des modèles personnalisés : L'exécution de modèles neuronaux personnalisés peut devenir coûteuse à volume élevé.
Google Document AI

Google domine l'intégration d'écosystèmes et l'analyse de mises en page multi-colonnes. Le moteur lui-même est puissant, mais la courbe d'apprentissage est abrupte, juste pour orchestrer l'automatisation de flux de travail basiques. La complexité l'emporte souvent par rapport aux avantages, surtout si vos besoins d'extraction sont relativement simples.
Avantages :
- Analyseurs spécialisés : Offre une vaste bibliothèque d'analyseurs spécialisés (par exemple, documents hypothécaires, approvisionnement, factures de services publics) entraînés sur des ensembles de données massifs.
- Intervention humaine (HITL) : Outils intégrés pour la révision humaine afin de gérer les extractions à faible confiance, ce qui est crucial pour les industries soumises à de fortes exigences de conformité.
- Analyse avancée de la mise en page : Exceptionnellement doué pour comprendre l'ordre de lecture, les paragraphes et les mises en page complexes grâce à l'héritage profond de Google en matière d'OCR.
Inconvénients :
- Complexité : Peut être excessivement complexe à configurer. Vous devez gérer les processeurs, les versions de processeurs et les autorisations IAM de GCP, ce qui implique une courbe d'apprentissage plus abrupte.
- Complexité de la tarification : Les coûts varient énormément selon si vous utilisez un processeur OCR de base, un analyseur spécialisé ou un modèle entraîné sur mesure.
Solutions basées sur les LLM (Claude, Gemini, ChatGPT... )
Les modèles vision-langage offrent une sortie sémantique novatrice, vous permettant d'interroger des champs spécifiques comme si vous parliez à un humain. Néanmoins, ces systèmes présentent une latence moyenne élevée et hallucinent fréquemment à grande échelle. Pour les flux de travail financiers soumis à de fortes exigences de conformité, l'injection d'hallucinations imprévisibles introduit un niveau de risque inacceptable.
Avantages :
- Maîtrise contextuelle : Les LLM peuvent comprendre le sens du texte. Ils peuvent identifier une "clause de résiliation" même si elle est formulée différemment dans 100 contrats différents.
- Extraction "zero-shot" : Vous n'avez pas besoin d'entraîner un modèle. Vous pouvez simplement demander : "Récupérez le nom du fournisseur, le montant total et les postes, et renvoyez-les au format JSON"
- Fenêtres de contexte massives : Des modèles comme Gemini 3.1 Pro peuvent ingérer des PDF entiers de 1 000 pages en une seule fois et extraire des données s'étendant sur plusieurs pages.
Inconvénients :
- Hallucinations : Les LLM peuvent occasionnellement "deviner" ou inventer des données si un champ est illisible ou manquant, tandis que les outils OCR traditionnels le laissent simplement vide.
- Manque de conscience spatiale : Les LLM sont généralement peu performants pour renvoyer les coordonnées exactes en pixels (boîtes englobantes) de l'emplacement du texte sur la page.
- Coûts/Latence imprévisibles : Le traitement d'images lourdes via un LLM peut être plus lent que l'OCR traditionnel, et la tarification basée sur les jetons rend difficile d'estimer précisément le coût d'une seule page.
Vous pouvez consulter un classement de référence à jour sur les modèles LLM.
Plateformes d'IA spécialisées
Les plateformes IDP (Traitement Intelligent de Documents) dédiées privilégient l'expérience développeur. Mindee, par exemple, fournit des API conviviales pour les développeurs afin d'extraire automatiquement des données structurées à partir de documents non structurés. Elles surpassent les API cloud génériques en proposant des modèles d'IA prêts à l'emploi pour les documents courants (comme les factures, les reçus et les passeports), ainsi qu'un constructeur d'API personnalisé pour entraîner des modèles sur mesure pour les documents spécifiques à l'entreprise.
Avantages :
- Expérience développeur (DX) supérieure : Elles offrent une documentation soignée, des SDK robustes (Python, Node, Go, etc.), des intégrations de webhooks faciles et des clés API en libre-service. Vous pouvez généralement faire fonctionner une preuve de concept en quelques minutes.
- La couche d'abstraction "intelligente" : Beaucoup de ces plateformes utilisent en fait Azure, AWS ou des LLM en coulisses. Elles agissent comme une couche d'orchestration, acheminant automatiquement votre document vers le meilleur moteur sous-jacent et unifiant le format de sortie afin que vous n'ayez pas à gérer plusieurs pipelines ML.
- Interface utilisateur intégrée pour la validation : Des plateformes comme Rossum et Mindee fournissent des interfaces utilisateur prêtes à l'emploi et intégrables. Si l'IA n'est pas sûre d'un champ, elle met le document en file d'attente dans une interface utilisateur élégante pour qu'un opérateur humain puisse cliquer et corriger, renvoyant automatiquement ces données pour affiner le modèle.
Inconvénients :
- La "prime de commodité" : Parce que vous payez pour une couche d'orchestration et d'interface utilisateur très soignée en plus du calcul de base, le coût par document peut être significativement plus élevé que d'interroger directement les API brutes d'AWS ou d'Azure.
- Risque de boîte noire : Étant donné que la plateforme gère le routage, vous avez moins de contrôle granulaire sur la manière dont les données sont extraites. Si un modèle sous-jacent change et affecte vos résultats, vous dépendez du fournisseur IDP pour le corriger.
- Surdimensionné pour les pipelines simples : Si vous avez juste besoin d'un script OCR rapide et simple pour déverser du texte dans une base de données, une plateforme IDP lourde introduit une complexité inutile.
{{cta-consideration-1="/in-progress/global-blog-elements"}}
Établir des critères de référence et d'évaluation
La fiabilité de l'extraction des postes réels et la latence moyenne dictent votre retour sur investissement opérationnel, rendant la précision brute de l'OCR une métrique de vanité inutile.
L'évaluation d'un benchmark de modèles IDP nécessite des tests confrontés à la réalité. Amazon Textract oblige les ingénieurs à naviguer dans un écosystème fragmenté de points de terminaison spécifiques.
Vous pourriez appeler détecter le texte du document pour le texte brut, analyser les dépenses pour les reçus, analyser les pièces d'identité pour les passeports, ou analyser les prêts pour les dossiers de prêt immobilier. Cette fragmentation transfère la majeure partie du travail à vos développeurs.
Évaluez plutôt vos alternatives en fonction de la précision géométrique et de la fiabilité des champs. Les API prêtes à la production fournissent des payloads structurés et immédiats. Mindee ne se contente pas de renvoyer le texte extrait ; elle fournit les coordonnées géométriques X/Y exactes (polygones / boîtes englobantes) de l'emplacement de ce texte sur la page. Ces données géométriques sont essentielles pour créer des interfaces utilisateur où un auditeur peut cliquer sur une donnée et voir exactement d'où elle provient.
.webp)
De plus, exigez des scores de confiance granulaires. Votre API doit fournir une évaluation de fiabilité (par exemple, Faible, Élevée, Certaine) indiquant le degré de certitude de l'IA concernant un champ extrait. Cela permet aux développeurs de pousser automatiquement les données vers les bases de données lorsque la certitude est élevée, tout en acheminant en toute sécurité les documents ambigus vers un réviseur humain.
.webp)
Calculer les considérations de coût et de performance
Les dépenses de configuration, la maintenance continue et le développement d'intégrations personnalisées éclipsent régulièrement les prix annoncés par page. Les grands fournisseurs de cloud semblent peu coûteux lorsqu'on analyse le coût brut de l'API pour 1 000 pages, mais ce calcul ignore les salaires d'ingénierie consommés par l'écriture de code HTTP passe-partout.
L' API d'analyse des dépenses et les outils génériques similaires ont de grandes difficultés avec la précision des postes dans les tableaux imbriqués. Si le moteur échoue sur des mises en page à plusieurs colonnes, votre équipe perdra des jours à écrire des expressions régulières pour corriger la sortie. Vous avez besoin de modèles de tarification prévisibles et d'outils solides pour compenser ces risques.
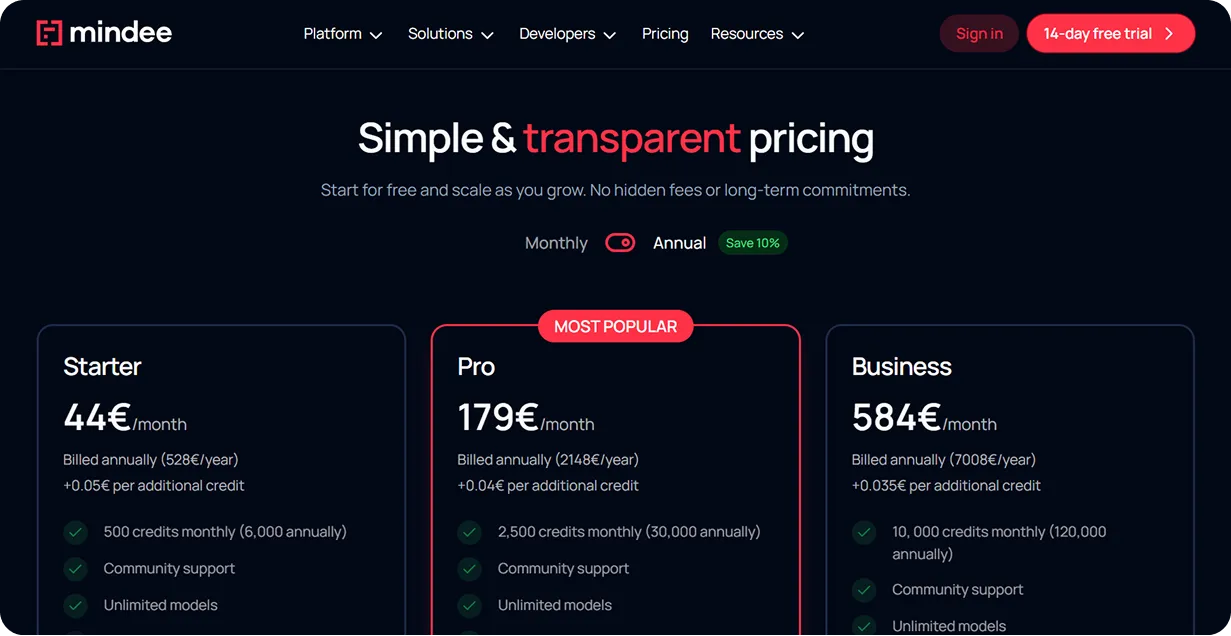
Les frais de traitement des données basés sur l'utilisation s'envolent de manière incontrôlable lors des pics de volume. Des modèles d'abonnement garantissent la stabilité. Mindee utilise un système de crédits où 1 crédit équivaut à 1 page traitée. Le forfait Starter offre 500 crédits pour 44 € par mois, tandis que le forfait Pro vous fait passer à 2 500 crédits pour 179 € par mois. Le forfait Business s'étend à 10 000 crédits pour 584 € par mois, et la tarification Enterprise personnalisée prend en charge des volumes massifs dépassant 250 000 crédits par an.
Vous pouvez également réduire considérablement les coûts en utilisant les SDK officiels (bibliothèques clientes). Mindee fournit des bibliothèques open source officiellement prises en charge en Python, Node.js, Java, .NET (C#), Ruby et PHP. Celles-ci offrent une sécurité de type, une gestion des erreurs intégrée et une auto-complétion du code, éliminant ainsi le besoin d'écrire des wrappers d'API REST personnalisés.
Concevoir l'intégration et la flexibilité des flux de travail
Un moteur d'extraction puissant échoue complètement s'il ne peut pas s'intégrer de manière transparente à votre stack existante et exécuter une logique de routage conditionnel. Amazon Augmented AI (A2I) propose des cadres de révision humaine mais vous enferme agressivement dans l'écosystème AWS. Les pipelines de traitement de documents modernes exigent une flexibilité d'intégration.
Les documents arrivent rarement parfaitement formatés, nécessitant un pré-traitement intelligent avant même le début de l'extraction.
Vous pouvez utiliser des outils comme Split de Mindee pour gérer les fichiers multipages en détectant automatiquement où les documents individuels commencent et se terminent. Ensuite, Classify agit comme un moteur de routage intelligent, catégorisant les fichiers entrants afin qu'ils déclenchent le pipeline d'extraction correct. Pour les images assemblées, comme trois reçus photographiés ensemble sur un bureau, Crop détecte les documents distincts, les isole et génère des fichiers séparés pour garantir que les données ne sont pas mélangées.
.webp)
Une fois les données extraites, les intégrations d'applications transparentes permettent à votre équipe d'agir rapidement. Les équipes opérationnelles sans ressources d'ingénierie dédiées peuvent s'intégrer directement aux plateformes No-Code comme Zapier, N8N et Make (anciennement Integromat). Pour les charges de travail importantes, les Webhooks renvoient activement les résultats JSON à votre système une fois que l'IA a terminé. Si vous avez besoin d'un contrôle absolu, vous pouvez interagir directement avec l'API RESTful via des requêtes HTTP POST standard.
Tirer parti de la personnalisation des modèles et des capacités de l'IA
Les systèmes hérités basés sur des modèles se brisent dès qu'un fournisseur modifie un logo ou décale une marge. Les plateformes d'extraction modernes utilisent des modèles linguistiques avancés et un apprentissage continu pour s'adapter dynamiquement, éliminant ainsi le besoin d'un mappage de coordonnées rigide.
L'avancée la plus profonde en matière de capacités d'IA est l'intégration du RAG (apprentissage continu).
Au lieu de réentraîner entièrement un modèle d'IA lorsqu'il échoue sur une nouvelle mise en page, vous corrigez l'erreur une seule fois. Le système mémorise cette correction et l'applique instantanément aux documents similaires à l'avenir, devenant plus intelligent au fur et à mesure. Vous pouvez également déployer facilement des couches de validation personnalisées. Vous pouvez extraire vos données automatiquement en créant un modèle d'extraction personnalisé sur Mindee. Téléchargez un exemple de facture et le système le transforme instantanément en un format JSON structuré.
Pour les organisations internationales, la localisation du traitement des données est une feature essentielle. Pour se conformer aux lois strictes sur la confidentialité comme le RGPD, les abonnements supérieurs vous permettent de forcer Mindee à traiter vos documents exclusivement dans des régions géographiques spécifiques (par exemple, uniquement en Europe) et d'appliquer des politiques de rétention strictes afin que vos données ne soient jamais stockées.
{{cta-consideration-1="/in-progress/global-blog-elements"}}
Appliquer l'extraction aux cas d'usage professionnels
Les API d'extraction spécialisées transforment les goulots d'étranglement spécifiques à l'industrie en pipelines hautement automatisés et prévisibles. Les fonctionnalités techniques abstraites n'ont de valeur que lorsqu'elles sont appliquées aux résultats commerciaux, et les limites de la détection de texte de base deviennent évidentes dans les environnements à enjeux élevés.
Le traitement des factures pour les comptes fournisseurs exige une extraction parfaite des postes, quelles que soient les variations infinies des fournisseurs. Une solution IDP doit capturer de manière fiable les totaux, les taux de taxe et les lignes de produits individuelles. L'automatisation de cette saisie de données accélère le rapprochement de fin de mois et élimine les retards de paiement des fournisseurs. Dans les services financiers et la logistique, la rapidité et la précision dictent le succès lors du traitement des connaissances, des déclarations douanières ou de l'évaluation du risque de prêt. Un seul chiffre omis sur une facture commerciale arrêtera les opérations d'expédition internationales. De même, le traitement des documents de réclamation dans le secteur de l'assurance nécessite l'analyse de données très peu structurées, allant des rapports d'incidents manuscrits aux factures médicales complexes. Les plateformes IDP spécialisées gèrent ces variations en appliquant une compréhension sémantique plutôt que des règles rigides.
Aligner votre stratégie d'extraction avec les objectifs commerciaux
L'alternative optimale à Textract minimise vos frais d'ingénierie tout en maximisant la précision des données dans toutes vos opérations. L'OCR brut est un problème résolu. Le défi actuel consiste à transformer des pixels de documents imprévisibles en un JSON propre et fiable auquel votre base de données fait implicitement confiance. Avant de signer un contrat cloud d'entreprise massif, testez vos documents non structurés les plus chaotiques avec une API pensée pour les développeurs. Évaluez la vitesse d'extraction, examinez les scores de confiance et mesurez l'effort d'intégration. La différence entre un pipeline fragile et un système d'automatisation robuste réside entièrement dans le choix de vos outils.
À propos
.svg)

.webp)

