
Data extraction API to automate document processing in seconds
Automate data extraction with an API that leverages AI and adaptive layout understanding to accurately extract data from unstructured documents
Cut processing costs by up to 95% while improving data quality
Try it for free
4.8/5 (30+ reviews)
.svg)
Trusted by top-tier teams worldwide

How automated document data extraction APIs work ?
1
Capture
2
Pre-processing
3
Data extraction
4
Enrichment
5
Validation

Smart capture image from poor quality phone pictures, handwritten notes to native PDFs
Bridge the gap between noisy inputs and structured data. Mindee API cleans low-quality phone captures, analyse handwriting, and isolate multi-documents on a single page/picture.
Auto-crop
Live test available
.webp)
AI-powered classification that identifies document "DNA" (Invoices vs. Contracts) and automates batch splitting
Manual document sorting is a bottleneck of the past. Our routing engine acts as a digital architect, instantly classifying documents and directing them to the correct business logic.
.webp)
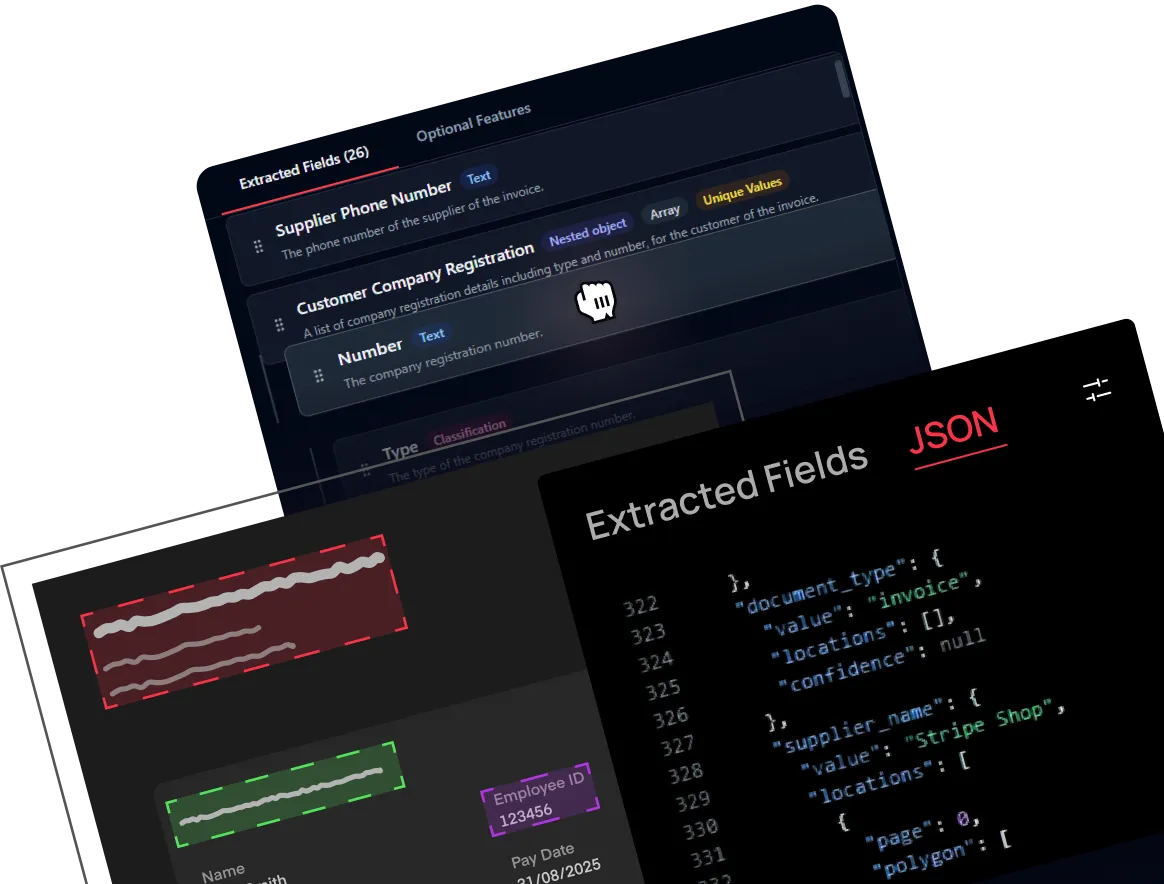
Extract data from any layout with outstanding accuracy : complex tables, key-value pairs, and handwritten annotations supported
Move beyond simple character recognition. Our extraction layer leverages Neural Networks to understand your data contextually, turning static unstructured files into dynamic, structured assets in standard JSON format.
.webp)
Real-time synchronization with ERP/CRM master data and automated third-party API validation (VAT, Compliance)
Data in a vacuum has limited utility. The "Enrich" phase bridges the gap between a document and your entire enterprise ecosystem (ERP, CRM, PLM) thanks to integrations.
.webp)
Automated business rule validation and high-efficiency Human-in-the-Loop workflows for edge-case validation.
Go beyond simple extraction. Build resilient document pipelines that automatically verify data against your custom business rules. Our API manages the friction between automated confidence scores and human edge-case validation, ensuring your production data is always clean, compliant, and actionable.
Confidence scores
Enterprise-grade
Mindee API capabilities to reduce wasted time on document processing

Custom extraction models
Start from our prebuilt models and modify the data schema, or set everything from scratch
Multi-formats/languages
Handle any document types (PDFs, JPEG, PNG,...)and return structured data in JSON format

Advanced OCR features
Confidence scores, continuous learning to refine your model and bounding boxes available

Live test available
On Mindee's app, you can live test your model set up. Update on‑the‑go with our AI assistant
SDKs/no-code integrations
Immediate time-to-value with our SDKs & no-code tools integration for developers

Enterprise-security grade
Host your data where you need (EU or US) and enjoy our SOC 2 Type II certified APIs
Ready-to-use Extraction models
Skip manual data entry while improving data accuracy and quality
Eliminate manual bottlenecks with an intelligent engine designed for accuracy. By combining layout-aware parsing and bounding boxes, we extract high-fidelity data from any format. Mindee API can go further by providing confidence scores about each field extracted. This feature allows you to set up automated workflow confidently, ensuring that every piece of information is verified against your specific operational requirements.
.webp)
.webp)
Text, OBJECT, TABLE smart Extraction
Extract data from complex layout: tables, line items, handwritten details, pictures...
Transform messy or complex inputs into structured intelligence. Whether handling structured documents, semi-structured documents, or completely unstructured documents, Mindee API ensures precise classification of data.
From PDFs to low-resolution scanned images, we extract critical key-value pairs, complex tables and line items with ease. By blending robust parsers and pre-built models with custom training for your unique custom documents, we bridge the gap between raw pixels and actionable data.
continuous learning model
Train and custom your extraction model to deal with every edge-case
Master the complexity of non-standard documents with an architecture built for total adaptability. Our platform moves beyond static extraction by leveraging continuous learning to refine performance.
By integrating RAG (Retrieval-Augmented Generation), you can upload documents to create a dynamic knowledge base of past corrections and specific business contexts. This ensures that even the most unique edge‑cases are handled with precision, turning rare exceptions into standard automated successes through a self-improving feedback loop.
.webp)
.webp)
one platform, total control
Advanced OCR features and more to give you full control about your extraction workflow
Our platform provides granular confidence scores and precise bounding boxes to ensure that every extraction is both verifiable and structurally accurate, and moving beyond simple "black-box" processing.
Empower your compliance strategy with localized processing zones and a strict "don't store my data" retention policy.
Integrated with seamless team collaboration tools, these features offer the architectural control required to turn complex document workflows into secure, high-precision automated assets tailored to your specific needs.
Invoice OCR
Extract line items and totals from global invoices in any language or format
Receipt OCR
Extract itemized totals, taxes, and merchant details from receipts in any format
Passport OCR
Capture identity data, MRZ, and expiry dates from any international passport
Resume OCR
Parse skills, work history, and contact info from diverse resumes and CV styles
Bank statement OCR
Digitize transactions, balances, and account details from multi-page statements
Driver's License OCR
Extract license numbers, classes, and addresses from diverse regional formats
.webp)

Developers and technical profiles already used it !
Add modern AI-based Mindee OCR API to your product, in minutes.

Mindee is an integrated document processing platform backed by reliable AI technology. The service has an intuitive and user-friendly interface and provides highly accurate results extracting data from various document types, especially financial receipts and invoices, which are relatively complex and require specialized optical character recognition (OCR) services. The platform provides seamless integration with our current data processing workflows through customizable APIs, allowing for efficient data extraction and automation.

Amar A.
Mindee is a software that helps us to convert all of our physical business data like bills, invoices, warranty cards, calendar, recipts received to us into a digital documents that can be stored in our drive and can be uploaded in different type of Excel sheets so that all the updates can be maintained and a proper analytics of transactions can be kept by the financial team
Shiv K.
Mindee is a web based tool that help us in scanning and reading different type of documents like identity cards, invoices, proposal plans etc and extract all the information with its AI and then it provides all the information and data associated with these documents a structured way.
Gaurav K.
Excellent. In addition to their great product, the sales team has always been proactive on how they could help us leverage the maximum results from their product. It was like having an additional product manager on our side
Jeff B.
Mindee works reliably and delivers good performance. The OCR data is accurate, and the API is stable. It works like a charm.
Manuel B.
Mindee is a web based tool that help us in scanning and reading different type of documents like identity cards, invoices, proposal plans etc and extract all the information with its AI and then it provides all the information and data associated with these documents a structured way.
Simon
.svg)
+15M documents processed monthly
Start to extract data at scale, now
+500 active users
14-day free trial
No credit card
.svg)
FAQ about Mindee's OCR API
Is a data document extraction API the same as a web scraping API ?
No. While both "extract data," the underlying technology is worlds apart.
- Web scraping APIs: Designed to navigate DOM structures, bypass CAPTCHAs, and collect data from HTML/CSS. They search for the right information before to extract anything.
- Data extraction APIs (Document AI): Specifically built to process "unstructured visual files" like PDFs, scanned images, and emails. They don't look for <div> tags; they use OCR and spatial vision to understand the layout of a physical page
Can I extract complex tables from scanned PDFs with Mindee ?
Yes,with Mindee,you can test this feature by signing up for free here and uploading a sample file. Line items and complex tables recognition will be fully supported from PDFs or any image formats.
This is where generalist APIs often fail. Standard OCR might give you a "word soup."
For complex tables (multi-line rows, merged cells, or nested headers), you need a vision-aware pipeline.
Pro tip: Generalist LLMs often hallucinate table structures. For "messy" financial documents, look for APIs that use specific vision models rather than just generic text-to-text models
How do I extract 10MB+ PDFs or long documents ?
With Mindee, you can handle up to 100MB size per file and up to 200 pages.
Large files (e.g., 100-page mortgage) should never be processed in a "request-response" (synchronous) loop. We can talk about two API methods :
- Asynchronous processing (Polling) : You submit the file, receive a job_id, and the API processes it in the background.
- Webhooks : Once complete, the API "pings" your server with the structured JSON. This is the gold standard for any Automated data extraction API setup for every language (Python, Node JS, Java, etc.)
How accurate are complex tables & line items across different layout ?
Mindee could be the best fit for you if you need a reliable API, to extract line items variations with high-level accuracy.
Accuracy varies significantly based on the layout. While "Key-Value Pairs" (like Total Amount or Date) are easy, Line Items (Description, Quantity, Unit Price) are the hardest to parse because every vendor uses a different table style.
Benchmark Tip: Don't trust the marketing "99% accuracy" claim. Test the same set of 50 "messy" invoices across vendors to see who misses line items or confuses the "Quantity" with the "Tax Rate."
How do I guarantee valid JSON structured format ?
Getting JSON is step one; getting valid JSON is step two. Most modern APIs, like Mindee allows you to define a data schema. To ensure your database doesn't crash:
- Use Pydantic (Python) or Zod (TypeScript) to validate the API output.
- If the extraction doesn't meet the schema (e.g., a missing mandatory invoice_id), flag it for human review.
What about data extraction from handwriting or multilingual documents ?
Mindee supports every alphabets, every languages, every handwritten human-readable documents.
Most top-tier APIs now support handwriting and 100+ languages. However, expect a 15-20% drop in confidence for cursive handwriting compared to printed text. For niche languages, verify if the OCR engine supports the specific character set (e.g., Cyrillic or Arabic).
What are some real-world examples of automated document data extraction ?
When it comes to automated document data extraction, Here are the most impactful real-world examples of how automated data extraction is used to eliminate manual entry:
In the accounts payable world, data extraction is the engine behind "touchless invoicing."When a vendor sends an invoice, the API doesn't just read the text; it extracts specific fields like the invoice number, tax ID, net amount, and total. Most importantly, it parses complex line-item tables, capturing every individual product, quantity, and unit price.
This allows the system to process payments automatically while ensuring that credit notes and statements are recorded with 100% accuracy.
It is a core component of two-way matching and reconciliation for supply chain management. By extracting the PO number from a purchase order and the SKU list from a corresponding delivery note, businesses can automatically verify that the items received match the items ordered. This automated extraction ensures that auditors have a clean, digital trail of exactly what was delivered versus what was requested, without a human ever having to cross-reference paper sheets.
For customer onboarding, automated extraction turns a slow, manual verification process into an instant check. When a user uploads their ID or a utility bill, the API extracts the full name, date of birth, and document expiration date. It also pulls the address and account number from utility bills to provide instant proof of residence. This allows companies to verify a customer’s identity in seconds, significantly reducing drop-off rates during the sign-up flow.
You can check more real-life examples of how companies leverage this technology by visiting customer stories.
