
.svg)



Sommaire
En tant que développeur, vous avez probablement déjà rencontré le défi de la correspondance de chaînes. Que vous créiez un correcteur orthographique, un moteur de recherche ou que vous essayiez de comparer des chaînes de votre base de données, les correspondances exactes ne suffisent pas toujours, en particulier lorsqu'il s'agit de fautes de frappe ou de texte généré par OCR.
Dans cet article, nous allons explorer des méthodes pratiques pour la correspondance approximative des chaînes à l'aide de Python. Nous aborderons les sujets suivants :
- Trois mesures populaires pour la similitude des chaînes : la distance de Jaccard, la plus longue sous-chaîne commune et la distance de Levenshtein.
- Comment tirer parti de bibliothèques Python telles que difflib, fuzzywuzzy, et regex.
- Exemples de code que vous pouvez adapter à la langue de votre choix.
Métriques pour une comparaison efficace des chaînes
L'appariement des chaînes dépend souvent de la comparaison de la similitude de deux chaînes, même si elles ne sont pas exactement identiques.
Le choix de la bonne métrique de similarité dépend de votre contexte : vous souciez-vous de la rapidité, de la précision ou de la tolérance aux fautes de frappe ?
Il existe de nombreuses méthodes pour mesurer la similitude des chaînes, mais nous en discuterons ci-dessous :
- La distance de Jaccard, idéal pour une comparaison rapide basée sur des ensembles.
- Le pourcentage de sous-chaîne commun le plus long, utile lorsque l'ordre des caractères est important.
- La similitude avec Levenshtein (qui peut également être utilisé pour calculer le score de confiance), idéal pour la tolérance typographique et le suivi des modifications.

Le choix de la métrique pour la comparaison de chaînes dépend largement des exigences spécifiques de votre application.
Par exemple, si vous avez affaire à de grands ensembles de données où les performances sont essentielles, des méthodes plus simples telles que la distance Jaccard peuvent être préférées en raison de leur rapidité.
Toutefois, si la précision est importante, en particulier dans les cas où l'ordre des caractères et les erreurs typographiques sont importants, des approches plus sophistiquées telles que la similarité de Levenshtein ou le pourcentage de sous-chaîne commun le plus long peuvent être plus appropriées.
Comprendre les forces et les faiblesses de chaque méthode vous aidera à choisir celle qui convient le mieux à vos besoins en matière de correspondance de chaînes !
La distance de Jaccard
L'une des méthodes les plus simples pour mesurer la similitude entre deux ensembles d'éléments consiste à utiliser la distance de Jaccard.
Essentiellement, il calcule le rapport entre le nombre de caractères uniques qui apparaissent dans les deux chaînes et le nombre total de caractères uniques qui se trouvent dans l'une des deux chaînes. Ce ratio fournit une représentation numérique claire de la similitude ou de la différence entre les deux chaînes en fonction de leurs contributions de caractères uniques.
Voici l'implémentation de la distance Jaccard en Python :
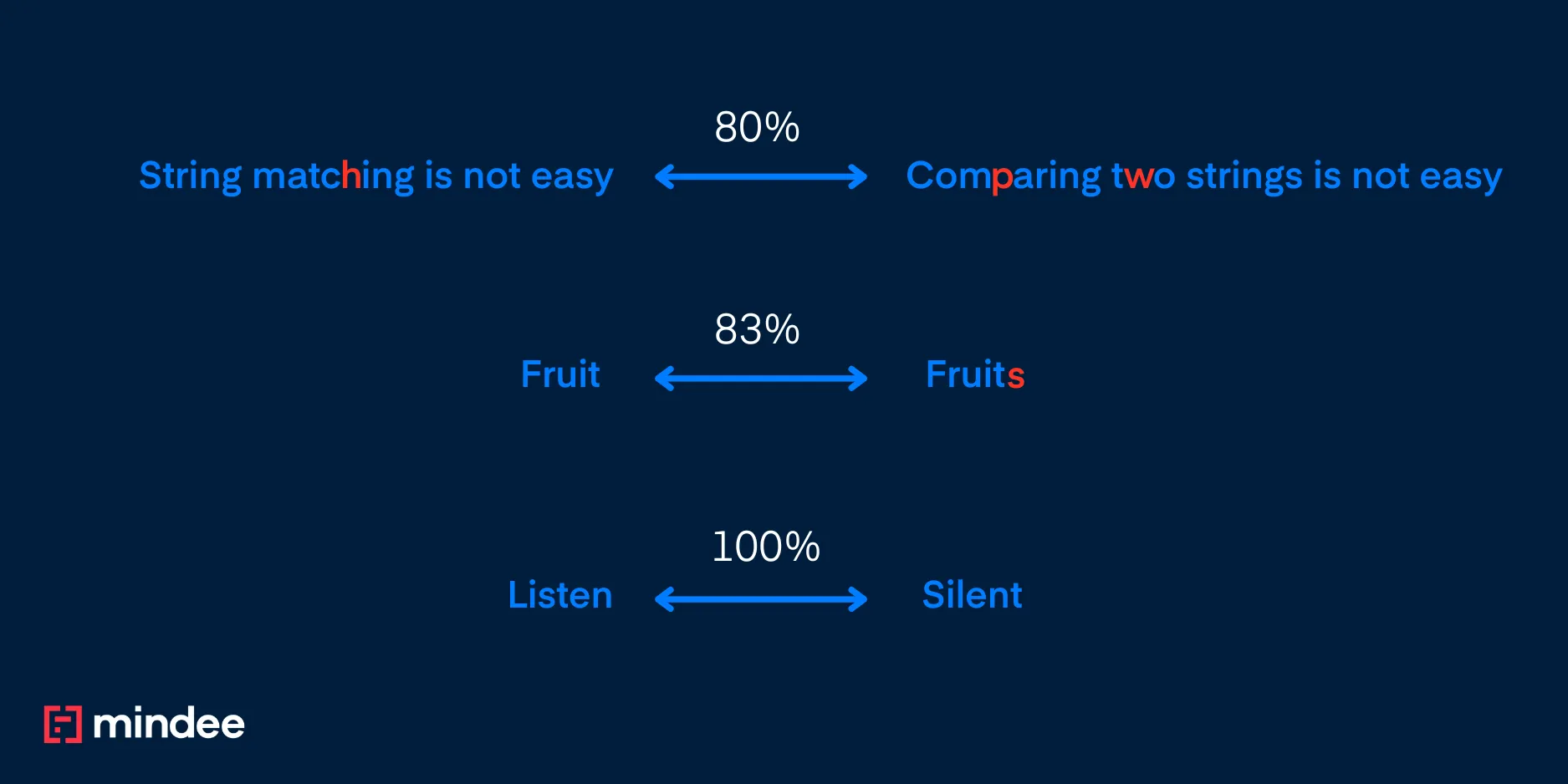
Par exemple, la similitude Jaccard entre « fruit » et « fruits » est 5/6.
Vous vous demandez peut-être quelle est l'efficacité de cette métrique ? Il est en fait assez simple et facile à mettre en œuvre, ce qui le rend très attrayant pour diverses applications. Cependant, une limitation importante est qu'il ne prend pas en compte l'ordre dans lequel les caractères apparaissent.
Par exemple, la distance Jaccard entre SILENT et LISTEN est... 1 — 6/6 = 0. Nous avons donc besoin de quelque chose de plus robuste.
Le pourcentage de sous-chaîne commun le plus long
Le sous-chaîne commune la plus longue fait référence à la plus longue séquence de caractères que l'on puisse trouver dans les deux chaînes données.
Pour visualiser ce concept, considérez deux chaînes, qui peuvent être des séquences de lettres ou de chiffres, et déterminez le segment de caractères qu'elles partagent en commun et qui est le plus long. Cette idée nous amène à trouver un moyen de mesurer la similitude des deux chaînes en calculant le ratio.
Ce ratio est déterminé en divisant la longueur de la plus longue sous-chaîne commune par la plus courte des deux chaînes. Cette approche nous permet de comprendre à quel point les chaînes sont étroitement liées les unes aux autres en fonction des caractères qu'elles contiennent.

Donc, dans les exemples ci-dessus :
- « Fruit » et « Fruits » donnent un score de 100 %, car le mot complet « Fruit » est la sous-chaîne courante la plus longue et
- « Écouter » et « Silent » donnent 1/3, car deux caractères (« en ») sur six sont courants
Selon votre cas d'utilisation, vous pouvez également calculer le ratio en utilisant la longueur maximale des deux chaînes :
- Utilisation de la longueur minimale : un score de 100 % signifie que l'une des deux chaînes est complètement incluse dans l'autre.
- Utilisation de la longueur maximale : un score de 100 % n'est possible que lorsque les deux chaînes sont exactement les mêmes.
Voici une implémentation python de cette méthode à l'aide de difflib :
Mais que se passe-t-il si je veux comparer « au revoir » et « au revoir » ? Eh bien, la sous-chaîne commune la plus longue est « goo », donc la similitude serait de 3/7, ce qui est très faible étant donné qu'un seul caractère diffère.
Similitude avec Levenshtein
Le Distance de Levenshtein est un concept utilisé pour mesurer la différence entre deux chaînes. Plus précisément, il calcule le nombre minimum de modifications qui doivent être apportées à une chaîne pour la transformer en une autre chaîne.
Ces modifications peuvent inclure des actions telles que l'insertion d'un caractère, sa suppression ou le remplacement d'un caractère par un autre.
En comptant ces variations, la distance de Levenshtein fournit une valeur numérique qui représente le niveau de dissemblance entre les deux chaînes comparées.
La distance de Levenshtein est en fait un exemple spécifique d'une catégorie plus large connue sous le nom de MODIFIER la distance.
Alors que la distance de Levenshtein attribue un poids uniforme de 1 à chaque type de modification, ce qui signifie que chaque insertion, suppression ou substitution compte de la même manière, la distance de modification permet généralement d'attribuer des poids différents aux différents types de modifications.
Cela signifie que dans le cas de la distance EDIT, vous pouvez hiérarchiser certaines modifications comme étant plus importantes que d'autres, ce qui permet une comparaison plus nuancée entre les chaînes.
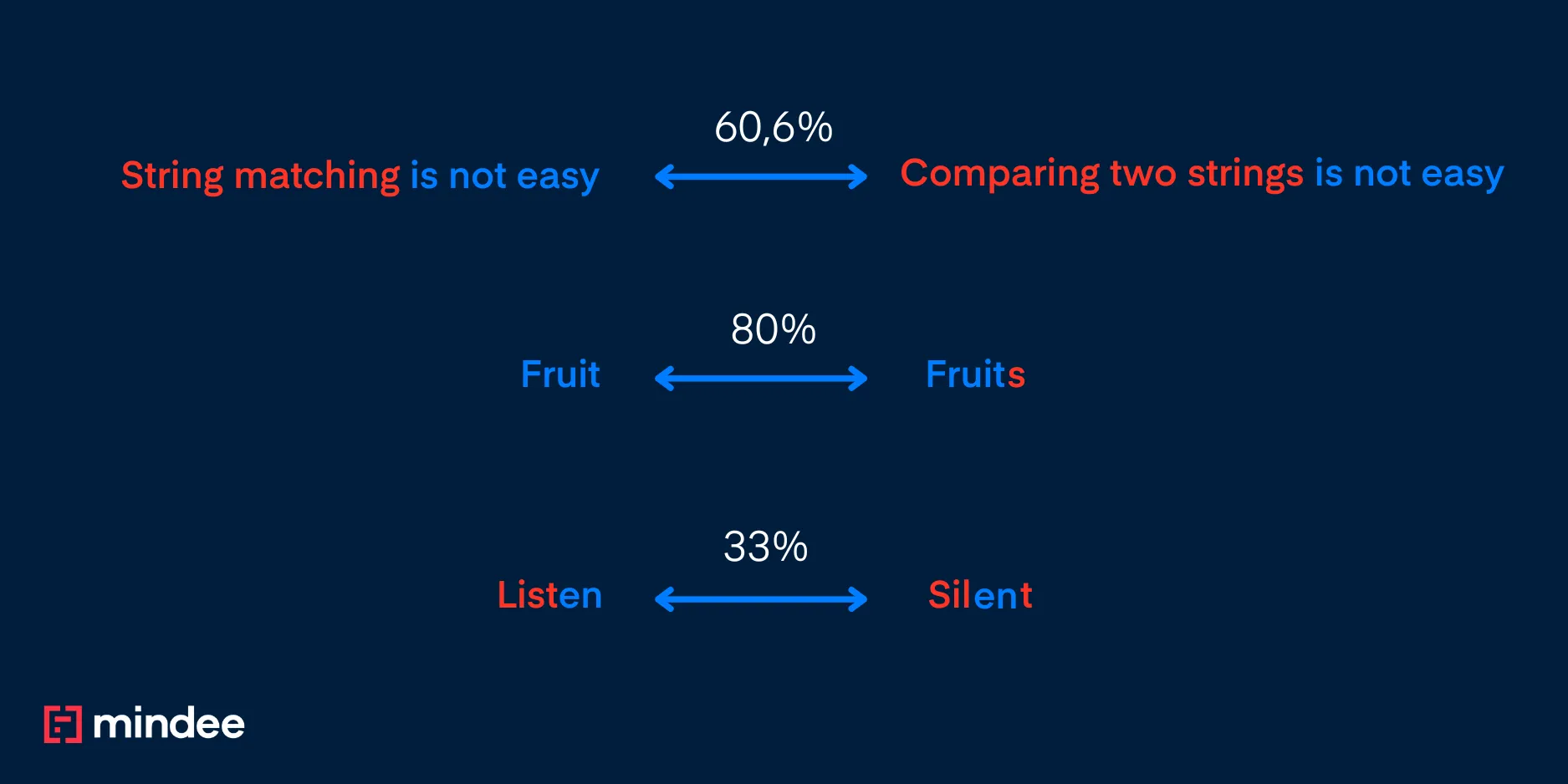
Donc, dans les exemples ci-dessus :
- « Fruit » et « Fruits » donnent un score de 80 % car une erreur est introduite par un « s » sur cinq caractères pour le mot le plus petit, donc 1- (1/5) correspond à 80 %
- « Listen » et « Silent » donnent 33 % car le nombre minimal d'opérations pour les faire correspondre est de 4 avec deux remplacements nécessaires, une insertion et une suppression, donc 1- (4/6) soit 33 %
La distance EDIT offre plus de flexibilité car il est possible d'ajuster les poids afin de mieux s'adapter à votre problème.
Une modification peut être de 3 types :
- Insérer: Ajoutez un caractère supplémentaire
- Supprimer: Supprimer un personnage
- Remplacer: Remplacer un caractère
NB: Parfois, la modification Remplacer n'est pas utilisée et est considérée comme une suppression plus une insertion. Vous pouvez également trouver quelques définitions, y compris la modification de transposition.
Pour obtenir un score de comparaison à partir de la distance de Levenshtein comme avec les autres méthodes, nous pouvons diviser la distance par la longueur de la chaîne la plus courte ou la plus longue.
Voici une implémentation d'un score de comparaison utilisant la distance de Levenshtein :
Comment effectuer une recherche autorisant les erreurs à l'aide d'expressions régulières ?
Le package regex en Python permet la recherche à l'aide d'expressions régulières qui permettent une recherche rapide dans les données textuelles. Ce package possède une fonctionnalité puissante qui permet une correspondance partielle des expressions régulières. Nous présenterons cette fonctionnalité et donnerons un avant-goût de sa puissance dans le paragraphe suivant.
Correspondance approximative avec Regex
Les expressions régulières sont utilisées pour définir un modèle de recherche et permettent de trouver des correspondances dans des chaînes. L'utilisation d'une correspondance approximative est possible à l'aide de packages tels que regex en python : il peut permettre la recherche d'un modèle avec quelques erreurs acceptables.
Les fonctionnalités de correspondance approximative de la bibliothèque regex sont particulièrement utiles dans les scénarios où les données peuvent être imparfaites ou contenir des erreurs, comme dans les sorties OCR.
En permettant un certain degré de flexibilité dans les modèles de recherche, les développeurs peuvent récupérer efficacement des informations pertinentes même lorsque les chaînes de saisie ne correspondent pas exactement. Cette fonctionnalité est inestimable dans des applications telles que l'analyse de texte, le nettoyage des données et le traitement du langage naturel, où la capacité de prendre en compte les variations et les erreurs peut améliorer considérablement la précision et la fiabilité des résultats.
Vous pourriez être intéressé par la recherche de mots clés dans un document numérisé présentant des erreurs d'OCR.
En fait, les erreurs d'OCR peuvent présenter des modèles récurrents (comme les suivants : « w » → (« vv » ou « v »), « O » → « 0 », « y » → « v »). Ainsi, en autorisant un nombre maximum d'erreurs ou en spécifiant le type d'erreur autorisé (insertion, suppression, substitution), nous pouvons trouver ces mots clés, comme dans les exemples ci-dessous :
L'identifiant permettant d'autoriser les erreurs générales est le suivant : {e}, ce faisant, nous ne précisons pas le nombre d'erreurs tolérées. Par conséquent, pour fixer une limite supérieure au nombre d'erreurs, nous utiliserons le signe « ≤ », par exemple, une limite supérieure de deux erreurs que nous utiliserons {e≤=2}.
De plus, nous pouvons spécifier le caractère introduisant l'erreur, qui peut être introduit par substitution/insertion formant l'erreur, en utilisant cet identifiant {e<=2 : [v]}.
La limite supérieure du nombre d'erreurs peut être plus précise, car nous pouvons la spécifier par type d'erreur, comme dans le dernier exemple ci-dessus : nous voulions que la somme du nombre de substitutions et du nombre d'insertions ne dépasse pas 2, ce qui donne cet identifiant {1s+1i<=2 : [v]}.
Vous pouvez également consulter notre article sur la façon de créer des produits d'IA!
Conclusion
Comme nous l'avons observé, de nombreuses techniques sont disponibles pour effectuer des recherches et des appariements approximatifs dans divers contextes. La complexité de ces techniques peut varier considérablement :
À une extrémité du spectre, nous avons des méthodes plus simples comme la distance de Jaccard, qui fournit un moyen simple de mesurer la similitude entre les ensembles.
À l'autre extrémité, nous rencontrons des approches plus sophistiquées, telles que la similarité de Levenshtein, qui calcule le nombre minimum de modifications d'un seul caractère requises pour transformer une chaîne en une autre.
De plus, ces méthodes peuvent être utilisées efficacement en conjonction avec des expressions régulières via Python regex bibliothèque. Cette intégration permet aux utilisateurs d'effectuer des recherches rapides et efficaces dans les données textuelles, ce qui facilite la localisation des modèles et la correspondance des chaînes en fonction de critères spécifiques.
À propos
.svg)

.webp)
.webp)

.webp)