
.svg)
.webp)
Sommaire
L' aperçu
Jusqu'à 90 % des données commerciales mondiales ne sont pas structurées. Si votre organisation s'appuie uniquement sur des lignes SQL structurées pour prévoir ses revenus trimestriels, vous volez à l'aveugle.
Des personnes auditant une entreprise de logistique qui a modélisé l'efficacité de l'ensemble de sa chaîne d'approvisionnement sur des horodatages de bases de données, en ignorant complètement les milliers d'e-mails PDF des fournisseurs contenant les raisons réelles des retards. Maîtriser l'extraction et l'analyse de données structurées et non structurées constitue le principal atout concurrentiel de l'ère de l'IA.
Dans ce guide, nous analysons les différences fondamentales entre ces types de données, comment ils évoluent et comment les modèles analytiques modernes transforment le chaos non structuré en informations exploitables.
Identifiez les données structurées pour une analyse quantitative immédiate
Les données structurées sont des informations quantitatives hautement organisées résidant dans des schémas fixes, ce qui les rend instantanément consultables et parfaites pour le traitement algorithmique.
Il repose sur un schéma prédéfini et une approche de schéma sur écriture. Le schéma en écriture impose que la base de données exige que les données soient conformes à une structure rigide avant de les écrire sur disque. En raison de cette organisation stricte, les équipes stockent généralement des données structurées dans des systèmes de gestion de bases de données relationnelles (SGBDR) et des entrepôts de données. Les analystes peuvent facilement interroger ces informations à l'aide du langage de requête structuré (SQL) et visualiser les résultats via des tableaux de bord interactifs de Tableau.
.webp)
Envisagez des systèmes CRM enregistrant les noms des clients, les dates des transactions et les montants d'achat spécifiques. La rigidité garantit une intégrité absolue des données mais limite considérablement la flexibilité. Vous ne pouvez pas forcer la saisie d'une réclamation client en texte libre dans un champ entier strict.
Exploitez des données non structurées pour découvrir un contexte commercial qualitatif
Les données non structurées ne disposent pas d'un modèle de données prédéfini, capturant des informations qualitatives au format natif qui nécessitent un traitement avancé pour être comprises.
Contrairement à son homologue structuré, il fonctionne selon une philosophie de schéma sur lecture. Le schéma en lecture signifie que les données conservent leur format brut jusqu'à ce qu'elles soient interrogées, ce qui permet une évolutivité massive. Les ingénieurs stockent les données non structurées principalement dans des lacs de données évolutifs, des systèmes de fichiers ou des bases de données NoSQL. En raison de son manque d'organisation inhérente, il nécessite un prétraitement intensif, un balisage des métadonnées et traitement du langage naturel (NLP) pour extraire de la valeur.
.webp)
Les exemples courants incluent les factures PDF, les e-mails internes, les systèmes de gestion des actifs numériques (DAM) et les transcriptions audio du service client. Vous ne pouvez pas simplement exécuter une requête SQL sur un fichier audio pour trouver des clients mécontents sans qu'une couche intermédiaire d'analyse des sentiments ne traduise cet audio en texte structuré.
En cas d'ingestion massive de documents, comme un PDF de 50 pages contenant l'équivalent d'une journée entière de courrier mixte, ce prétraitement devient un véritable cauchemar. Pour résoudre ce problème, les développeurs utilisent des outils tels que la fonctionnalité Mindee Split. L'IA détecte le début et la fin de chaque document individuel, divisant automatiquement le gros fichier en documents logiques distincts.
Tirez parti des données semi-structurées comme solution intermédiaire flexible
Les données semi-structurées abandonnent les formats tabulaires rigides mais utilisent des balises et des marqueurs sémantiques pour établir une hiérarchie flexible et lisible par machine.
Ce format ne repose pas sur un SGBDR strict mais reste bien plus organisé que le texte brut. Il s'appuie largement sur des métadonnées et des marqueurs sémantiques pour séparer des éléments distincts et appliquer une hiérarchie.
Les charges utiles JSON, les fichiers XML, les CSV et les journaux de capteurs IoT entrent tous dans cette catégorie. Lorsque les développeurs transmettent des données de flux de clics entre des applications Web modernes, ils utilisent le format JSON, car il fournit la hiérarchie nécessaire sans exiger une mise à jour rigide de la table de base de données pour chaque nouveau type d'événement.
Comparez les règles de stockage et d'évolutivité pour chaque type de données
Les solutions de stockage divergent fortement en fonction du type de données : les données structurées nécessitent des bases de données relationnelles pour assurer leur cohérence, tandis que les données non structurées prospèrent dans le stockage d'objets évolutif.
Les entreprises transfèrent généralement des données structurées vers des entrepôts de données basés sur le cloud pour des requêtes rapides. À l'inverse, les formats non structurés vivent dans des lacs de données ou dans des espaces de stockage d'objets. Nous voyons fréquemment des équipes d'ingénierie tenter d'intégrer du texte non structuré dans des bases de données relationnelles, ce qui entraîne des tableaux gonflés, des modifications de schéma douloureuses et une dégradation des performances. Le compromis moderne réside dans les architectures Lakehouse, un système hybride combinant la capacité de stockage massive d'un lac de données avec le solide cadre de gouvernance des données d'un entrepôt.
Vous pourriez objecter : pourquoi ne pas tout stocker absolument dans un lac de données bon marché ? Sans outils stricts de gouvernance des données, de balisage des métadonnées et de catalogage, un lac de données se dégrade rapidement en un marécage de données inutile, où il est pratiquement impossible de trouver un PDF historique spécifique.
Pour éviter cela, les organisations mettent en œuvre un routage intelligent. En analysant les fichiers entrants, une IA peut agir comme un moteur de routage intelligent pour les classer automatiquement par type (par exemple, en identifiant si un fichier est un contrat, une facture, une fiche de paie ou un identifiant). Avec un outil tel que Mindee Classify, vous pouvez trier les documents instantanément et les acheminer vers le pipeline d'extraction approprié avant qu'ils n'atteignent votre couche de stockage.
{{cta-awareness-1= » /in-progress/global-blog-elements "}}
Évaluez les avantages, les inconvénients et les défis de gestion de votre architecture de données
Les données structurées permettent des requêtes fluides mais manquent de flexibilité pour les nouveaux types de données ; les données non structurées offrent une profondeur et un contexte considérables, mais présentent de graves complexités d'intégration des données.
Le principal avantage des données structurées est qu'elles sont prêtes à être utilisées pour les algorithmes d'apprentissage automatique et la surveillance des KPI. L'inconvénient est son manque de flexibilité ; les modifications de schéma nécessitent des frais d'ingénierie et des temps d'arrêt importants. Les données non structurées reflètent la réalité granulaire des goulots d'étranglement de la chaîne d'approvisionnement et du sentiment des clients. L'inconvénient majeur est qu'il nécessite une expertise avancée en science des données et une gestion rigoureuse des données pour être utilisée.
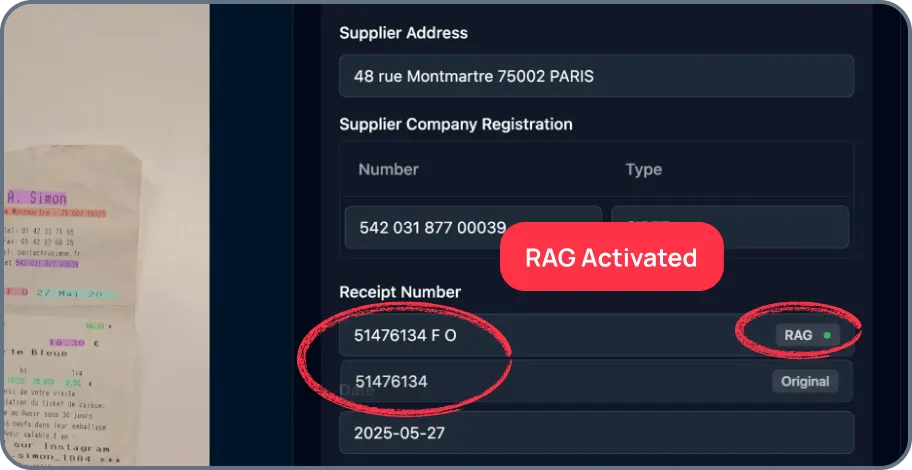
J'ai vu des équipes chargées des données consacrer des semaines à écrire des scripts regex personnalisés pour analyser des documents PDF désordonnés, mais tout le pipeline s'interrompait lorsqu'un fournisseur modifiait la mise en page de ses factures de deux pixels. Au lieu de réentraîner complètement un modèle d'IA lorsqu'il rencontre des difficultés avec une nouvelle mise en page de document, il suffit de corriger l'erreur une seule fois. Plateformes avec RAG (Apprentissage continu), comme Mindee, mémorisez cette correction et appliquez-la instantanément à des documents similaires à l'avenir, de manière plus intelligente à la volée.
Déployez l'IA et l'apprentissage automatique pour extraire de la valeur de formats non structurés
L'intelligence artificielle moderne, en particulier le traitement du langage naturel et la vision par ordinateur, est le pont qui transforme le chaos non structuré en données JSON structurées et exploitables.
Historiquement, l'extraction de données à partir d'images ou de texte libre nécessitait des équipes de saisie manuelle offshore. Aujourd'hui, les plateformes d'analyse de documents alimentées par l'IA fournissent des API conviviales aux développeurs pour extraire automatiquement des données structurées à partir de documents non structurés. Le produit principal de Mindee Extract extrait automatiquement les données structurées (totaux, taxes, dates, noms, rubriques du tableau) à partir de documents non structurés tels que des PDF ou des photos.
Ce qui le rend vraiment puissant pour les flux de travail des entreprises, c'est l'ajout de mesures de fiabilité. L'API donne une cote de fiabilité (faible, élevée, certaine, par exemple) pour chaque champ extrait. Cela permet aux développeurs de transférer automatiquement les données vers leur base de données lorsque l'IA est certaine, tout en acheminant en toute sécurité les documents confus ou flous vers un humain pour une révision manuelle.
Les ingénieurs n'ont même pas besoin d'écrire du code HTTP standard pour y parvenir ; Mindee fournit des SDK open source officiellement pris en charge pour Python, Node.js, Java, .NET (C#), Ruby et PHP.
Alignez votre stratégie d'extraction de données sur des objectifs de revenus concrets
Évitez d'extraire les données dans le vide ; adaptez votre architecture de données directement à la génération de revenus et à des objectifs de business intelligence tangibles.
L'objectif ultime de toute entreprise moderne est de combiner des données quantitatives avec des informations qualitatives. Cette approche unifiée permet de créer des tableaux de bord interactifs et des modèles de segmentation de la clientèle extrêmement précis.
Envisagez des marques de commerce électronique qui fusionnent des données transactionnelles (SQL) avec des évaluations de produits traitées par NLP (texte non structuré). En analysant cet ensemble de données combiné, ils ajustent les messages marketing et prévoient les besoins en stocks avec précision, plutôt que de deviner en se basant uniquement sur le volume historique des ventes. L'extraction n'a de valeur que lorsqu'elle produit un résultat.
Combler le fossé entre les données structurées et le chaos non structuré
Le fossé historique entre les données structurées et non structurées est en train de disparaître rapidement. Alors que ces formats nécessitent des architectures de stockage et des modèles analytiques totalement différents, l'IA moderne permet aux équipes d'ingénierie de traiter les fichiers non structurés comme des actifs interrogeables instantanément.
N'essayez pas de faire bouillir l'océan en réorganisant l'architecture complète de votre lac de données d'entreprise en une seule fois. Identifiez plutôt un goulot d'étranglement de données non structurées hautement manuel et sujet aux erreurs, tel que la saisie des factures des fournisseurs ou le traitement de contrats de plusieurs pages, et mettez en œuvre un pipeline d'extraction automatisé dès aujourd'hui.
À propos
.svg)

.webp)
.webp)

.webp)