
.svg)
.webp)
Table of Contents
The snapshot
Up to 90% of worldwide business data is unstructured. If your organization relies solely on structured SQL rows to forecast quarterly revenue, you are effectively flying blind.
People auditing a logistics firm that modeled their entire supply chain efficiency on database timestamps, completely ignoring the thousands of PDF vendor emails containing the actual reasons for delays. Mastering the extraction and analysis of both structured and unstructured data is the definitive competitive moat of the AI era.
In this guide, we break down the fundamental differences between these data types, how they scale, and how modern analytical models turn unstructured chaos into actionable intelligence.
Identify structured data for immediate, quantitative analysis
Structured data is highly organized, quantitative information residing in fixed schemas, making it instantly searchable and perfect for algorithmic processing.
It relies on a predefined schema and a schema-on-write approach. Schema-on-write dictates that the database requires data to conform to a rigid structure before writing it to disk. Because of this strict organization, teams typically store structured data in relational database management systems (RDBMS) and data warehouses. Analysts can easily query this information using structured query language (SQL) and visualize the results via interactive Tableau dashboards.
.webp)
Consider CRM systems recording customer names, transaction dates, and specific purchase amounts. The rigidity ensures absolute data integrity but severely limits flexibility. You cannot force a free-text customer complaint into a strict integer field.
Tap into unstructured data to uncover qualitative business context
Unstructured data lacks a predefined data model, capturing qualitative, native format information that requires advanced processing to understand.
Unlike its structured counterpart, it operates on a schema-on-read philosophy. Schema-on-read means data retains its raw format until queried, allowing for massive scalability. Engineers store unstructured data primarily in scalable data lakes, file systems, or NoSQL databases. Because it lacks inherent organization, it requires heavy preprocessing, metadata tagging, and natural lanuage processing (NLP) to extract value.
.webp)
Common examples include PDF invoices, internal emails, digital asset management (DAM) systems, and customer service audio transcripts. You cannot simply run an SQL query on an audio file to find angry customers without an intermediate sentiment analysis layer translating that audio into structured text.
When dealing with massive document ingestion—like a 50-page PDF containing a whole day's worth of mixed mail—this preprocessing becomes a nightmare. To solve this, developers use tools like the Mindee Split feature. The AI detects where each individual document begins and ends, automatically splitting the large file into logical, separate documents.
Leverage semi-structured data as the flexible middle ground
Semi-structured data abandons rigid tabular formats but utilizes tags and semantic markers to establish a flexible, machine-readable hierarchy.
This format does not rely on a strict RDBMS but remains far more organized than raw text. It relies heavily on metadata and semantic markers to separate distinct elements and enforce a hierarchy.
JSON payloads, XML files, CSVs, and IoT sensor logs all fall into this category. When developers pass clickstream data between modern web applications, they use JSON because it provides necessary hierarchy without demanding a rigid database table update for every novel event type.
Contrast the storage and scalability rules for each data type
Storage solutions diverge sharply based on data type: structured data demands relational databases for consistency, while unstructured data thrives in scalable object storage.
Organizations typically push structured data into cloud-based data warehouses for fast querying. Conversely, unstructured formats live in data lakes or object storage. We frequently see engineering teams attempt to force unstructured text into relational databases, leading to bloated tables, painful schema changes, and degraded performance. The modern compromise is lakehouse architectures—a hybrid system blending the massive storage capacity of a data lake with the robust data governance framework of a warehouse.
You might object: why not store absolutely everything in a cheap data lake? Without strict data governance tools, metadata tagging, and cataloging, a data lake quickly degrades into a useless data swamp, where finding a specific historical PDF is virtually impossible.
To prevent this, organizations implement intelligent routing. By analyzing incoming files, an AI can act as an intelligent routing engine to automatically categorize them by type (e.g., identifying whether a file is a contract, an invoice, a pay slip, or an ID). With a tool like Mindee Classify, you can sort documents instantly and route them to the correct extraction pipeline before they hit your storage layer.
{{cta-awareness-1="/in-progress/global-blog-elements"}}
Weigh the pros, cons, and management challenges of your data architecture
Structured data offers seamless querying but lacks flexibility for novel data types; unstructured data provides immense depth and context but introduces severe data integration complexities.
The primary advantage of structured data is its readiness for machine learning algorithms and KPI monitoring. The downside is its inflexibility; schema changes require significant engineering overhead and downtime. Unstructured data captures the granular reality of supply chain bottlenecks and customer sentiment. The distinct disadvantage is that it demands advanced data science expertise and rigorous data wrangling to utilize.
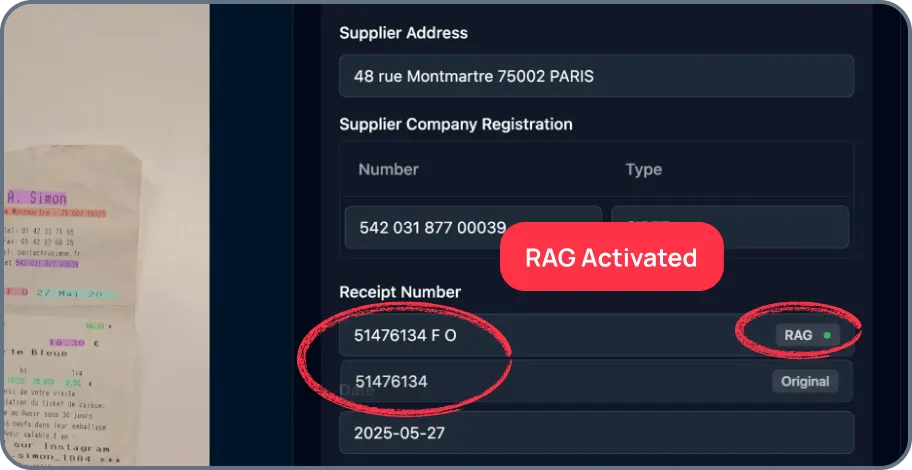
I have watched data teams burn weeks writing custom regex scripts to parse messy PDF documents, only to have the entire pipeline break when a vendor changes their invoice layout by two pixels. Instead of fully retraining an AI model when it struggles with a new document layout, you just correct the error once. Platforms with RAG (Continuous Learning)—like Mindee—remember this correction and instantly apply it to similar documents in the future, getting smarter on the fly.
Deploy AI and machine learning to extract value from unstructured formats
Modern artificial intelligence, specifically natural language processing and computer vision, is the bridge that transforms unstructured chaos into structured, actionable JSON data.
Historically, extracting data from images or free text required offshore manual entry teams. Today, AI-powered document parsing platforms provide developer-friendly APIs to automatically extract structured data from unstructured documents. The core Mindee Extract product automatically pulls structured data (totals, taxes, dates, names, table line items) from unstructured documents like PDFs or photos.
What makes this truly powerful for enterprise workflows is the addition of reliability metrics. The API gives a reliability rating (e.g., Low, High, Certain) for every extracted field. This lets developers automatically push data to their database when the AI is certain, while safely routing confusing or blurry documents to a human for manual review.
Engineers do not even need to write boilerplate HTTP code to achieve this; Mindee provides officially supported, open-source SDKs for Python, Node.js, Java, .NET (C#), Ruby, and PHP.
Align your data extraction strategy with concrete revenue goals
Avoid extracting data in a vacuum; map your data architecture directly to revenue generation and tangible business intelligence goals.
The ultimate goal for any modern enterprise is combining quantitative data with qualitative insights. This unified approach powers interactive dashboards and highly accurate customer segmentation models.
Consider e-commerce brands merging transactional data (SQL) with NLP-processed product reviews (unstructured text). By analyzing this combined dataset, they adjust marketing messaging and predict inventory needs accurately, rather than guessing based on historical sales volume alone. Extraction is only valuable when it drives an outcome.
Bridge the gap between structured data and unstructured chaos
The historical divide between structured and unstructured data is rapidly dissolving. While these formats demand entirely different storage architectures and analytical models, modern AI allows engineering teams to treat unstructured files as instantly queryable assets.
Do not attempt to boil the ocean by re-architecting your entire enterprise data lake at once. Instead, identify one highly manual, error-prone unstructured data bottleneck—such as vendor invoice entry or multi-page contract processing—and implement an automated extraction pipeline today.
About
.svg)

.webp)
.webp)
.webp)