
.svg)


Sommaire
L' aperçu
Imaginez que vous vous fiez à un OCR solution qui alimente votre système avec des données erronées : les totaux des factures sont mal lus, les noms des clients sont incohérents ou les codes produits sont mal interprétés. Cela semble frustrant, non ? C'est pourquoi Précision de l'OCR n'est pas qu'une fonctionnalité, c'est le pilier de toute solution d'automatisation des documents !
Qu'il s'agisse de créer une application, de rationaliser les opérations ou de rechercher une efficacité maximale, il est essentiel de comprendre la précision de l'OCR pour choisir le bon fournisseur.
Dans ce guide, nous allons expliquer ce que signifie réellement la précision de l'OCR, pourquoi elle est si cruciale pour votre entreprise et comment l'évaluer efficacement. Nous explorerons des indicateurs essentiels tels que Taux de correspondance exacts, Taux d'erreur de texte (WER), et Taux d'erreur de caractères (CER) pour vous aider à mesurer la précision.
Mais la précision à elle seule ne suffit pas à tout. Nous allons donc également nous pencher sur des indicateurs de performance plus généraux, notamment Score de F1 et Taux d'automatisation, pour garantir votre API OCR livre là où ça compte.
Puisque nous croyons qu'il faut passer de la parole aux actes, nous allons conclure par une étude de cas montrant comment Mindee calcule la précision de l'OCR dans un scénario réel. À la fin, vous aurez toutes les informations nécessaires pour choisir la solution d'OCR adaptée à votre entreprise.
Avant de vous y plonger davantage, sachez que vous pouvez également télécharger L'outil de référence gratuit de Mindee!
Prêt à décoder l'API OCR la mieux adaptée à vos besoins ? Allons-y !
Qu'est-ce que la précision de l'OCR ?
Définition de la précision de l'OCR
Précision de l'OCR fait référence à la précision avec laquelle un système OCR (reconnaissance optique de caractères) peut transcrire le texte d'une image ou d'un document numérisé dans un format lisible par machine.
Il s'agit d'une mesure quantitative de la mesure dans laquelle les données extraites correspondent à la vérité réelle (la valeur attendue inscrite dans le document), généralement exprimée en pourcentage ou par le biais de mesures telles que Taux de correspondance exact, Taux d'erreur de texte (WER), ou Taux d'erreur de caractères (CER).
Pour les entreprises, l'obtention d'une précision OCR élevée est essentielle pour minimiser les erreurs en aval, garantir la fiabilité des données et réduire l'effort manuel requis pour la validation et la correction.
Pourquoi la précision est-elle importante pour choisir votre solution d'OCR ?
Qu'il s'agisse du traitement des factures, des contrats légaux, des reçus ou des pièces d'identité, la précision a un impact direct sur l'efficacité, les coûts et la prise de décision.
Une solution peu précise entraîne des erreurs fréquentes, parfois difficiles à repérer, ce qui peut entraîner de longues interventions manuelles, un gaspillage de ressources et des problèmes potentiels de qualité des données.
Au contraire, un système OCR de haute précision fournit :
- Moins d'erreurs et de corrections manuelles : une haute précision minimise les taux d'erreur, ce qui réduit le travail manuel nécessaire pour valider et corriger les données extraites, ce qui est particulièrement crucial pour les entreprises qui gèrent le traitement de gros volumes de documents.
- Tâches de meilleure qualité : les utilisateurs pourront se concentrer sur des tâches à forte valeur ajoutée, car les quelques documents à consulter seront les plus délicats.
- Meilleurs taux d'automatisation : une haute précision renforce la confiance dans les flux de travail entièrement automatisés. Lorsque votre OCR est toujours précise, vous pouvez l'intégrer en toute confiance dans les processus sans avoir besoin d'une supervision humaine.
- Des processus plus rapides car moins d'interactions manuelles.
- Des expériences client et utilisateur améliorées : pour les applications destinées aux clients (par exemple, les applications mobiles qui scannent des pièces d'identité ou des reçus), la précision est synonyme de satisfaction des utilisateurs. Des interprétations erronées peuvent mener à de mauvaises expériences et saper la confiance dans votre produit.
- Conformité et diminution des risques : dans des secteurs tels que la finance, la santé et le droit, où la précision n'est pas négociable, les inexactitudes peuvent entraîner des problèmes de conformité ou des erreurs coûteuses.
- Évolutivité : une précision fiable garantit qu'à mesure que vos volumes de traitement de documents augmentent, vos opérations restent évolutives sans compromettre la qualité ou la rapidité.
Quand évaluation de la tarification des solutions d'OCR, la précision est la référence, mais la véritable valeur réside dans la compréhension de la manière dont elle s'intègre à des indicateurs de performance plus larges tels que la vitesse, la fiabilité et l'adaptabilité à votre cas d'utilisation commercial unique.
{{cta-awareness-1= » /in-progress/global-blog-elements "}}
Les meilleurs indicateurs pour évaluer la précision d'une OCR
Taux de correspondance exact par champ (EMR)
Qu'est-ce que l'EMR ?
Le Taux de correspondance exact (EMR) est un indicateur essentiel pour évaluer la précision de l'OCR, en particulier pour les cas d'utilisation où extraction de données est obligatoire.
Il mesure le pourcentage de champs d'un document dont la sortie OCR est correspond exactement aux données de vérité sur le terrain, sans aucune contradiction.
Cette métrique est particulièrement utile lors de l'extraction de données à partir de formulaires standardisés tels que des factures, des reçus ou des pièces d'identité, où chaque champ (par exemple, « Montant total », « Numéro de facture » ou « Date ») doit être correct pour que le document soit pleinement utilisable.
Pour chaque champ d'un jeu de données, la valeur extraite du système OCR est comparée à la valeur réelle (vérité fondamentale). L'EMR est ensuite calculé comme suit :
Par exemple, si un système OCR traite 1 000 champs et en extrait correctement 950, l'EMR serait de 95 %.
Quand donner la priorité à l'EMR ?
Le taux de correspondance exact par champ doit être une considération primordiale lors de l'évaluation des solutions d'OCR si votre entreprise s'appuie sur documents structurés et le précision totale des domaines individuels sont essentiels, comme l'information financière, la conformité fiscale ou la logistique.
En vous concentrant sur cette métrique, vous vous assurez que votre système fournit en permanence des sorties fiables qui minimisent les corrections manuelles et préservent l'intégrité des données.
Le WER (taux d'erreur de texte)
Qu'est-ce que WER ?
Taux d'erreur de texte (WER) est une métrique largement utilisée pour évaluer la précision de l'OCR, en particulier dans les scénarios où l'accent est mis sur la reconnaissance de texte plutôt que sur l'extraction de données structurées.
Il mesure combien de mots de la sortie OCR diffèrent de la vérité de base, en tenant compte des substitutions, des suppressions et des insertions.
WER est exprimé en pourcentage, les valeurs les plus faibles indiquant une précision plus élevée. Il est particulièrement utile dans des applications telles que la numérisation de documents, la transcription de texte manuscrit ou la reconnaissance de texte multilingue.
La formule pour WER est la suivante :
Ici :
S : Nombre de substitutions (mots erronés remplacés par des mots incorrects).
D : Nombre de suppressions (mots oubliés par le système OCR).
DANS : Nombre d'insertions (mots supplémentaires ajoutés par erreur).
N : Nombre total de mots contenus dans la vérité fondamentale.
Par exemple, si le texte de base contient 100 mots et que le système OCR introduit 5 substitutions, 3 suppressions et 2 insertions, le WER serait :
Quand donner la priorité à WER ?
WER est très utile pour évaluer les performances d'OCR pour reconnaissance de texte libre, tels que l'archivage de livres et de manuscrits, l'automatisation de la transcription de notes de réunion ou de documents juridiques ou la numérisation de documents historiques ou de fichiers numérisés contenant beaucoup de texte.
En combinant WER avec d'autres indicateurs tels que Taux de correspondance exact ou Taux d'erreur des caractères, vous pouvez réaliser une évaluation plus complète des performances d'OCR adaptée à votre cas d'utilisation spécifique.
Le CER (taux d'erreur de caractères)
Qu'est-ce que le CER ?
Taux d'erreur de caractères (CER) est un autre indicateur clé pour évaluer la précision de l'OCR, en se concentrant sur la précision au niveau des caractères plutôt que sur les mots ou les champs.
Il mesure combien de caractères de la sortie OCR diffèrent de la vérité de base, en tenant compte des substitutions, des suppressions et des insertions, par rapport au nombre total de caractères de la vérité de base.
Le CER est particulièrement utile dans les scénarios où les limites des mots peuvent ne pas exister (par exemple, données numériques, codes alphanumériques) ou lorsque la reconnaissance exacte des caractères est essentielle, comme les numéros de série, les codes de produit ou les données financières.
La formule du CER est la suivante :
Où :
- S : Nombre de substitutions de caractères (les mauvais caractères remplacent les bons).
- D : Nombre de caractères supprimés (caractères manqués par le système OCR).
- DANS : Nombre d'insertions de caractères (caractères supplémentaires ajoutés par erreur).
- N : Nombre total de personnages dans la vérité de base.
Par exemple, si le texte de base contient 1 000 caractères et que le système OCR introduit 10 substitutions, 5 suppressions et 3 insertions, le CER serait le suivant :
Quand donner la priorité à la CER ?
Le CER est le plus précieux lorsque précision au niveau des caractères est crucial, comme les transactions financières, la logistique et la chaîne d'approvisionnement ou la documentation technique.
Lorsqu'il est combiné à d'autres indicateurs tels que Taux d'erreur dans les mots (WER) ou Taux de correspondance exact (EMR), CER fournit une évaluation plus complète des performances de l'OCR, vous permettant de prendre des décisions éclairées adaptées à votre cas d'utilisation spécifique.
La distance de Levenshtein
Quelle est la distance entre Levenshtein ?
Maintenant que nous avons discuté du taux d'erreur, examinons de plus près la métrique qui le sous-tend.
Le Distance de Levenshtein, également connu sous le nom de Modifier la distance, est une métrique utilisée pour mesurer la différence entre deux chaînes.
Il calcule le nombre minimum d'opérations à caractère unique (insertions, suppressions et substitutions) nécessaires pour transformer une chaîne en une autre.
Lors de l'évaluation de l'OCR, la distance de Levenshtein est utilisée pour quantifier dans quelle mesure la sortie de l'OCR correspond à la réalité de base au niveau des caractères, fournissant ainsi un aperçu de la précision du système lors de la capture du texte.
Contrairement aux métriques qui mesurent la précision relative (par exemple, CER ou WER), la distance de Levenshtein fournit une mesure absolue de l'erreur.
La distance de Levenshtein entre deux chaînes est déterminée en construisant une matrice où :
- Les lignes représentent les caractères d'une chaîne.
- Les colonnes représentent les caractères de l'autre chaîne.
- La matrice est remplie en calculant le coût d'alignement de chaque caractère, sur la base du coût minimum des insertions, suppressions ou substitutions requis à chaque étape.
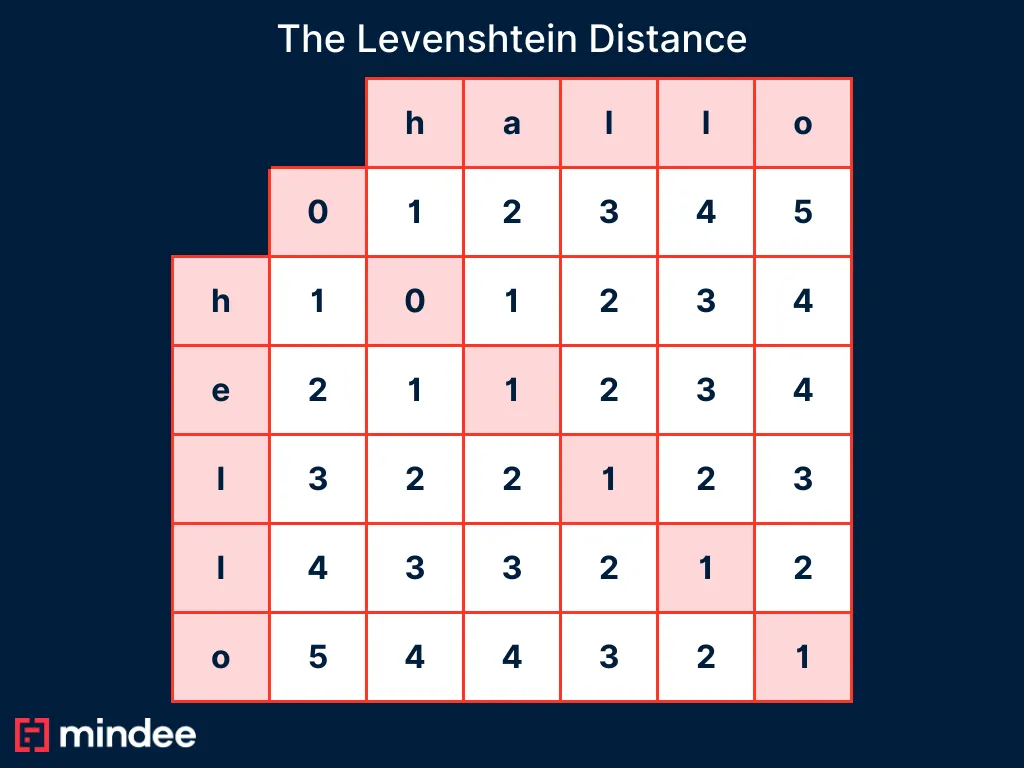
Par exemple, pour calculer la distance de Levenshtein entre »allo« et »bonjour« :
Substituer »un« avec »e« → Coût : 1 opération.
→ La distance de Levenshtein est 1.
Quand donner la priorité à la distance de Levenshtein ?
La distance de Levenshtein est particulièrement utile pour les comparaisons de textes courts, la reconnaissance de texte manuscrit ou pour comparer des résultats similaires.
Pour rendre la distance de Levenshtein plus exploitable dans les évaluations OCR, elle est souvent normalisée en pourcentage en la divisant par la longueur de la chaîne la plus longue, ce qui donne un score relatif similaire à Taux d'erreur des caractères (CER).
En combinant la distance de Levenshtein avec le CER et le taux de correspondance exact (EMR), vous pouvez créer une évaluation complète des performances d'OCR adaptée aux besoins de votre entreprise.
Au-delà de la précision : comment évaluer les performances globales de l'API OCR
En matière d'OCR, la précision n'est qu'une partie de l'histoire. Bien sûr, il est essentiel que votre OCR donne le bon texte, mais qu'en est-il de la vue d'ensemble ? Peut-il gérer rapidement de grands volumes de données ? Est-ce qu'il fonctionne de manière cohérente sur les différents types de documents ?
Pour évaluer une API d'OCR, il faut aller au-delà de la précision et se concentrer sur les métriques qui mesurent sa fiabilité, efficacité, et performance dans le monde réel. C'est là que des outils tels que le score F1 ou le taux d'automatisation entrent en jeu, comblant le fossé entre précision et rappel pour vous donner une image complète !
Le score de la F1
Le score F1 est une métrique de performance qui représente la moyenne harmonique de précision et rappel.
Il est particulièrement utile en OCR lorsque vous extrayez des données structurées ou semi-structurées, telles que des champs d'une facture ou des éléments d'un reçu.
Le score F1 quantifie la capacité d'un système d'OCR à équilibrer ces deux aspects :
- Précision: proportion de valeurs correctement extraites par rapport à toutes les valeurs extraites par le système OCR.
- Rappel: la proportion de valeurs correctement extraites par rapport à toutes les valeurs qui auraient dû être extraites (c'est-à-dire la vérité fondamentale).
Le score F1 garantit que ni la précision ni le rappel ne sont prioritaires de manière disproportionnée, ce qui vous donne une métrique unique pour évaluer l'efficacité globale du système.
La formule du score F1 est la suivante :
Un score F1 inférieur indique de meilleures performances, avec un valeur idéale de 1, ce qui signifie que le système OCR atteint une précision et un rappel parfaits.
Supposons qu'un système OCR traite 100 champs. Il décide de prédire quelque chose pour 80 champs. Sur les 80 champs extraits, 70 sont corrects.
Puis :
- Précision = 70/80 = 0,875
- Rappel = 70/100 = 0,7
Ce score de F1 de 0,778 indique que le système d'OCR est assez efficace mais qu'il peut encore être amélioré.
Quand prioriser le score F1 ?
Le score F1 est particulièrement utile pour évaluer les systèmes d'OCR pour l'extraction de données structurées ou pour comparer les performances d'OCR sur des ensembles de données complexes.
En intégrant le score F1 à votre évaluation, vous pouvez vous assurer que votre solution d'OCR répond non seulement aux normes de précision, mais également aux des critères de performance plus étendus sont nécessaires pour une intégration parfaite dans vos flux de travail.
Le taux d'automatisation
Quel est le taux d'automatisation ?
Le taux d'automatisation est un indicateur de performance qui mesure l'efficacité d'un système OCR flux de travail entièrement automatisés sans nécessiter d'intervention manuelle.
Alors que des indicateurs de précision tels que Taux de correspondance exact ou Score de F1 sont essentiels pour évaluer la précision de l'OCR, le taux d'automatisation va au-delà de l'exactitude : il vous indique dans quelle mesure vos données peuvent être traitées de bout en bout sans intervention humaine.
Concrètement, le taux d'automatisation reflète le pourcentage de documents ou de champs qui sont entièrement traités correctement par le système OCR, ne nécessitant aucune révision ou correction manuelle.
Cette métrique est essentielle pour dimensionner les opérations de traitement des documents et réduire les coûts opérationnels.
La formule du taux d'automatisation est la suivante :
Par exemple, si une solution d'OCR traite 1 000 documents et que 850 d'entre eux sont traités sans aucune intervention manuelle, le taux d'automatisation est de :
Quand prioriser le taux d'automatisation ?
Le taux d'automatisation est particulièrement utile dans les scénarios où l'intervention manuelle représente un gain de temps considérable ou coût au processus. C'est également un bon indicateur pour garantir traitement de gros volumes de documents ou une intégration fluide avec d'autres systèmes (comme un logiciel CRM).
En vous concentrant sur le taux d'automatisation aux côtés des mesures de précision traditionnelles, vous obtenez une vision globale des performances d'un système OCR dans des applications réelles. Il ne s'agit pas seulement d'obtenir les bonnes données : il s'agit de savoir dans quelle mesure vous pouvez réellement automatiser le processus.
La précision de l'OCR est la pierre angulaire de l'automatisation fiable des documents, mais ce n'est qu'une pièce du puzzle. Des indicateurs tels que Taux de correspondance exact (EMR), Taux d'erreur de texte (WER), et Taux d'erreur de caractères (CER) garantissent la précision, tandis que des indicateurs tels que Score de F1 et Taux d'automatisation évaluez les performances et l'évolutivité dans le monde réel.
La meilleure solution d'OCR allie précision, automatisation et adaptabilité à vos besoins spécifiques. En combinant les informations de ce guide avec les priorités de votre entreprise, vous pouvez choisir en toute confiance une API OCR qui fournit des données précises, réduit les tâches manuelles et évolue efficacement.
{{cta-conversion-1= » /en cours/éléments de blog mondiaux "}}
Découvrez la précision de l'OCR en action : l'outil de référence gratuit et le cas d'utilisation de Mindee
Choisir la bonne API d'OCR est une décision basée sur des données, et des outils comme celui de Mindee outil de référence OCR gratuit peut simplifier le processus.
Cet outil vous permet d'évaluer la précision de l'OCR à l'aide d'ensembles de données et de mesures réels tels que le taux de correspondance exact, le taux d'erreur de texte, etc. Il s'agit d'une ressource inestimable pour comparer les fournisseurs et trouver celui qui répond le mieux aux besoins de votre entreprise.
Pour voir ces concepts en action, regardez la vidéo ci-dessous, dans laquelle nous présentons une étude de cas réelle utilisant la solution OCR de Mindee.
Vous découvrirez comment les mesures de précision se traduisent en taux d'automatisation et en efficacité opérationnelle, en proposant un exemple pratique de la manière d'évaluer les performances de l'OCR pour votre propre cas d'utilisation.
Regardez la vidéo dès maintenant pour découvrez comment Mindee aborde la précision de l'OCR et comment vous pouvez appliquer ces principes pour choisir le meilleure API OCR pour votre entreprise !
Êtes-vous prêt à transformer vos flux de travail ? Commencez par les indicateurs qui comptent le plus pour vous !
À propos
.svg)

.webp)
.webp)

.webp)