
.svg)


Sommaire
L' aperçu
Dans le monde du machine learning, il ne s'agit pas seulement de faire des prédictions, mais sur la certitude de ces prévisions. Pensez à une voiture autonome qui doit décider de s'arrêter à une intersection ou non, ou à une IA du secteur de la santé diagnostiquant l'état d'un patient : les scores de confiance indiqueront dans quelle mesure un modèle peut être sûr de ses prévisions, cela aide les entreprises et les décideurs à agir avec plus de certitude.
Cependant, comme les humains, les modèles de machine learning comportent parfois des erreurs lors de la prédiction d'une valeur à partir d'un point de données d'entrée. Et tout comme les humains, la plupart des modèles sont en mesure de fournir des informations sur la fiabilité de ces prévisions.
Quand vous dites « Je suis sûr que... » ou « Peut-être que c'est... », dans les faits, vous êtes en train d'attribuer une qualification relative à votre niveau de confiance à propos de ce que vous dites. En mathématiques, ces informations peuvent être modélisées, par exemple sous forme de pourcentage, c'est-à-dire un nombre compris entre 0 et 1, et la plupart des technologies de machine learning fournissent ce type d'informations : le score de confiance.
Une équivalence homme-machine pour ce niveau de confiance pourrait être la suivante :
« Je suis sûr que... » <=> 100 %
« Je pense que c'est... » <=> 70 %
« Je ne sais pas mais je dirais... » <=> < 50 %
Le principal problème avec ce niveau de confiance est que vous dites parfois « Je suis sûr » même si vous vous trompez, ou « Je n'en ai aucune idée mais je dirais... » même si vous avez raison.
Évidemment, dans une conversation humaine, vous pouvez poser plus de questions et essayer d'obtenir une qualification plus précise de la fiabilité du niveau de confiance exprimé par la personne en face de vous. Mais lorsque vous utilisez un modèle de machine learning et que vous n'obtenez qu'un nombre compris entre 0 et 1, comment devriez-vous y faire face ?
Pourquoi les scores de confiance sont importants
Les scores de confiance sont bien plus que de simples chiffres abstraits qui circulent dans votre pipeline de machine learning; ils constituent la pierre angulaire qui peut améliorer ou défaire l'efficacité de l'ensemble de votre modèle lorsqu'il s'agit de scénarios du monde réel.
Pensez-y : Est-ce qu'un modèle pour approuver un prêt, signaler une transaction ou diagnostiquer un patient vous intéresserait s'il ne pouvait pas vous dire dans quelle mesure il est certain de ses prévisions ? C'est là que les scores de confiance entrent en jeu !

Imaginons que vous gérez un site e-commerce alimenté par un moteur de recommandation qui conseille vos clients sur les achats à effectuer. Un modèle avec un score de confiance élevé serait en mesure de proposer en toute confiance, par exemple, un nouveau produit, en sachant qu'il est susceptible de convertir. Mais si vous n'êtes sûr qu'à 60 %, vous pourriez ne pas suivre cette recommandation et proposer un produit best-seller plus fiable. Cette prise de décision nuancée n'est pas seulement intelligente ; elle augmente directement vos ventes tout en préservant la satisfaction de vos clients.
Les scores de confiance deviennent encore plus critiques dans le domaine des soins de santé. Supposons, par exemple, que le modèle travaille avec des médecins pour diagnostiquer des maladies. Si un modèle prédit le diagnostic avec un taux de confiance de 98 %, c'est normal pour les médecins ; ils ont des raisons d'étayer leur opinion. Mais lorsque ce chiffre tombe à, disons, 55 %, il est temps de revérifier et d'effectuer d'autres tests. Pour les cas de vie ou de mort, ces scores ne sont pas des chiffres mais une mince deuxième ligne d'assurance qui pourrait simplement contribuer à sauver des vies.
Ou imaginez un monde de détection des fraudes dans le secteur des services financiers : si le modèle détecte une transaction comme frauduleuse avec un taux de confiance de 95 %, vous pouvez facilement bloquer cette transaction en sachant que vous en informerez le client. Si ce score est d'environ 70 %, il est probablement préférable d'en informer le client tout en laissant la transaction se poursuivre, afin de minimiser les frictions inutiles tout en protégeant les comptes.
Dans tous ces cas, les scores de confiance vous aident à trouver le juste équilibre entre automatisation et intervention humaine, entre risque et récompense. C'est la recette secrète qui rend le machine learning non seulement intelligent, mais aussi pratique, fiable et sûr !
Vous pouvez également consulter notre article sur correspondance partielle de chaînes!
{{cta-awareness-1= » /in-progress/global-blog-elements "}}
Scores de confiance courants en matière de machine learning
Il n'existe pas de définition standard du terme « score de confiance » et vous pouvez en trouver de nombreuses variantes en fonction de la technologie que vous utilisez. Mais en général, c'est un ensemble ordonné de valeurs que vous pouvez facilement comparer les unes aux autres.
Les trois principaux types de scores de confiance que vous êtes susceptible de rencontrer sont les suivants :
Remarque technique importante : Vous pouvez facilement passer de l'option #1 à l'option #2 ou de l'option #2 à l'option #1 en utilisant n'importe quelle fonction bijective transformant [0, +∞ [points dans [0, 1], avec une fonction sigmoïde, par exemple (technique largement utilisée). N'oubliez pas qu'en raison de la précision de la virgule flottante, vous risquez de perdre l'ordre entre deux valeurs en passant de 2 à 1 ou de 1 à 2. Essayez de calculer le sigmoïde (10000) et le sigmoïde (100000), les deux peuvent vous donner 1.
Quelques indicateurs de machine learning pour comprendre le problème
La plupart du temps, une décision est prise en fonction des données saisies. Par exemple, si vous conduisez une voiture et que vous recevez le point de données « feu rouge », vous allez (espérons-le) vous arrêter.
Lorsque vous utilisez un modèle de machine learning pour faire une prédiction qui aboutit à une décision, vous devez faire réagir l'algorithme de manière à ce que la décision soit moins dangereuse si elle est erronée, car les prédictions ne sont par définition jamais correctes à 100 %.
Pour mieux comprendre cela, examinons les trois principaux indicateurs utilisés pour les problèmes de classification : fiabilité, mémoire et précision. Nous pouvons étendre ces métriques à d'autres problèmes que la classification.
Vrais positifs, vrais négatifs, faux positifs et faux négatifs
Ces définitions sont très utiles pour calculer les métriques. D'une manière générale, ils font référence à un problème de classification binaire, dans laquelle une prédiction est faite (« oui » ou « non ») sur des données dont la vraie valeur est « oui » ou « non ».
Dans les sections suivantes, nous utiliserons les abréviations tp, tenn., fp et fn.
Exactitude
La précision (ou acc) est la métrique la plus facile à comprendre. C'est tout simplement le nombre de prédictions correctes sur un ensemble de données. Dans le cas d'un jeu de données de test de 1 000 images par exemple, pour calculer la précision, il vous suffira de faire une prédiction pour chaque image, puis de compter la proportion de bonnes réponses dans l'ensemble de données.
Supposons que vous fassiez 970 bonnes prédictions à partir de ces 1 000 exemples : cela signifie que la précision de votre algorithme est de 97 %.
Cette métrique est utilisée lorsqu'il n'y a pas de compromis intéressant entre une prédiction faussement positive et une prédiction faussement négative.
Mais parfois, en fonction de votre objectif et de la gravité de vos décisions, vous souhaitez déséquilibrer le fonctionnement de votre algorithme en utilisant d'autres indicateurs tels que le rappel et la précision.
Formule de précision : (tp + tn)/(tp + tn + fp + fn)
Mémoire (également appelé sensibilité)
Pour calculer la mémoire de votre algorithme, vous devez prendre en compte uniquement les « vraies » données étiquetées de votre ensemble de données de test, puis calculer le pourcentage de bonnes prédictions. C'est un indicateur utile pour répondre à la question suivante : »Sur toutes les vraies valeurs positives, quel pourcentage mon algorithme prévoit-il réellement comme vrai ?»
Si un modèle ML doit prédire si un feu rouge est rouge ou non afin que vous sachiez si vous devez utiliser votre voiture ou non, préférez-vous une prédiction erronée qui :
- dit « rouge » même si ce n'est pas le cas
- dit « pas rouge » alors que c'est le cas
Voyons ce qui va se passer dans ces deux cas :
- Votre voiture s'arrête alors qu'elle ne devrait pas. Ce n'est que légèrement dangereux, car les autres conducteurs peuvent être surpris et cela peut provoquer un petit accident de voiture.
- Votre voiture ne s'arrête pas au feu rouge. Cela est très dangereux car un conducteur de passage à niveau risque de ne pas vous voir, de provoquer un accident de voiture à pleine vitesse et de causer des dommages ou des blessures graves.
Tout le monde convient que le cas (b) est bien pire que le cas (a). Dans ce scénario, nous voulons donc que notre algorithme ne dise jamais que la lumière n'est pas rouge alors qu'elle l'est : nous avons besoin d'une valeur de mémoire maximale, qui ne peut être atteinte que si l'algorithme prédit toujours « rouge » lorsque la lumière est rouge, même si cela se fait au détriment de la prédiction du « rouge » lorsque la lumière est réellement verte.
Le rappel peut être mesuré en testant l'algorithme sur un ensemble de données de test. Il s'agit d'un pourcentage qui divise le nombre de points de données que l'algorithme a prédit « Oui » par le nombre de points de données contenant réellement la valeur « Oui ».
Par exemple, supposons que nous ayons 1 000 images avec 650 lumières rouges et 350 lumières vertes. Pour calculer le rappel de notre algorithme, nous allons faire une prédiction sur nos 650 images de lumières rouges. Si l'algorithme indique « rouge » pour 602 images sur ces 650, le rappel sera de 602/650 = 92,6 %. Ce n'est pas suffisant ! Dans 7 % des cas, il existe un risque d'accident de voiture à pleine vitesse. Nous verrons plus loin comment utiliser le score de confiance de notre algorithme pour éviter ce scénario, sans rien changer au modèle.
Formule de rappel : tp/(tp + fn)
Précision (également appelée « valeur prédictive positive »)
La précision de votre algorithme vous donne une idée de la confiance que vous pouvez lui accorder lorsqu'il prédit « vrai ». Il s'agit de la proportion de prédictions correctement considérées comme « vraies » par rapport à toutes les prédictions considérées comme « vraies » (certains d'entre eux étant en fait « faux »).
Imaginons maintenant qu'un autre algorithme examine une route à deux voies et réponde à la question suivante : « Puis-je dépasser la voiture devant moi ? »
Encore une fois, voyons à quoi conduirait une fausse prédiction. Des prédictions erronées signifient que l'algorithme dit :
- « Tu peux dépasser la voiture » mais tu ne peux pas
- « Non, tu ne peux pas dépasser la voiture » même si tu peux
Voyons ce qui se passerait dans chacun de ces deux scénarios :
- Vous augmentez la vitesse de votre voiture pour dépasser la voiture qui vous précède et vous vous déplacez sur la voie de gauche (en sens inverse). Cependant, il se peut qu'une autre voiture arrive à pleine vitesse dans la direction opposée, ce qui provoquerait un accident de voiture à pleine vitesse. Résultat : vous êtes tous les deux gravement blessés.
- Vous pourriez dépasser la voiture qui vous précède, mais vous resterez doucement derrière le conducteur lent. Résultat : rien ne se passe, vous venez de perdre quelques minutes.
Encore une fois, tout le monde convient que (b) est un meilleur scénario que (a). Nous voulons que notre algorithme puisse prédire « vous pouvez dépasser » uniquement lorsque c'est vrai : nous avons besoin d'une précision maximale, ne dites jamais « oui » quand c'est réellement « non ».
Pour mesurer la précision d'un algorithme sur un ensemble de tests, nous calculons le pourcentage de « oui » réel parmi toutes les prédictions « oui ».
Pour ce faire, supposons que nous ayons 1 000 images de situations de dépassement, 400 d'entre elles représentant une situation de dépassement en toute sécurité, 600 d'entre elles étant dangereuses. Nous aimerions savoir quel est le pourcentage de prédictions « sûres » réelles parmi toutes les prédictions « sûres » faites par notre algorithme.
Disons que parmi nos images de prédictions « sûres » :
- 382 d'entre elles sont des situations de dépassement sûres : vérité = oui
- 44 d'entre eux sont des situations de dépassement dangereuses : vérité = non
La formule pour calculer la précision est la suivante : 382/ (382+44) = 89,7 %.
Cela signifie que 89,7 % du temps, lorsque votre algorithme indique que vous pouvez dépasser la voiture, vous le pouvez réellement. Mais cela signifie également que 10,3 % du temps, votre algorithme indique que vous pouvez dépasser la voiture même si ce n'est pas sûr. La précision n'est pas suffisante, nous verrons comment l'améliorer grâce au score de confiance.
Précision formule : tp/(tp + fp)
Résumé des métriques
Vous pouvez estimer les trois métriques suivantes à l'aide d'un jeu de données de test (plus il est grand, mieux c'est) et calculer :
Comment définir des seuils de score de confiance efficaces
Les scores de confiance sont essentiels pour interpréter la fiabilité des prédictions des modèles de machine learning. Ces scores se situent souvent dans un domaine spécifique intervalle (par exemple, 0 à 1), reflétant la certitude du modèle quant à ses prédictions. Les scores de confiance dans les tâches d'OCR, par exemple, sont façonnés pendant la phase d'apprentissage et peuvent être affinés grâce à des méthodes telles que le seuillage pour améliorer la fiabilité du texte extrait.
Prenons l'exemple d'une tâche de classification : un score de confiance de 0,8 peut indiquer que le modèle attribue une probabilité de 80 % à une classe donnée. Cependant, la compréhension de ces scores nécessite souvent de prendre en compte des intervalles de confiance pour tenir compte de l'incertitude et de la variabilité, en particulier lorsque l'on travaille avec des échantillons de taille limitée.
Dans tous les cas précédents, nous considérons que nos algorithmes ne peuvent prédire que « oui » ou « non ». Mais ces prédictions ne sont jamais émises sous la forme « oui » ou « non », il s'agit toujours d'une interprétation d'un score numérique. En fait, la machine prédit toujours « oui » avec une probabilité comprise entre 0 et 1 : c'est notre score de confiance.
En tant qu'être humain, la manière la plus naturelle d'interpréter une prédiction comme un « oui » étant donné un score de confiance compris entre 0 et 1 est de vérifier si la valeur est supérieure à 0,5 ou non. Ce 0,5 est notre valeur seuil, en d'autres termes, c'est le score de confiance minimum au-dessus duquel une prédiction est considérée comme « oui ». S'il est inférieur, nous considérons la prédiction comme « non ».
Cependant, comme nous l'avons vu dans nos exemples précédents, le coût des erreurs varie en fonction de nos cas d'utilisation.
Heureusement, nous pouvons modifier cette valeur de seuil pour que l'algorithme réponde mieux à nos besoins. Imaginons, par exemple, que nous utilisions un algorithme qui renvoie un score de confiance compris entre 0 et 1. La définition d'un seuil de 0,7 signifie que vous allez rejeter (c'est-à-dire considérer la prédiction comme « non » dans nos exemples) toutes les prédictions dont le score de confiance est inférieur à 0,7 (inclus). Ce faisant, nous pouvons affiner les différentes métriques.
En général :
- Augmenter le seuil réduira la mémoire et améliorera la précision
- Diminution du seuil fera le contraire
Il est important de souligner maintenant que les trois indicateurs ci-dessus sont tous liés. Voici une illustration simple :
- seuil = 0 implique que votre algorithme dit toujours « oui », car tous les scores de confiance sont supérieurs à 0. Vous obtenez la précision minimale (vous vous trompez sur chaque donnée « non » réelle) et le maximum de rappel (vous prédisez toujours « oui » quand c'est un vrai « oui »)
- seuil = 1 implique que vous rejetez toutes les prédictions, car tous les scores de confiance sont inférieurs à 1 (inclus). Vous avez 100 % de précision (vous ne vous trompez jamais en disant « oui », comme on ne dit jamais oui..), 0 % de mémorisation (... parce que vous ne dites jamais « oui »)
Essayer de fixer le meilleur seuil de score n'est rien d'autre qu'un compromis entre précision et mémorisation.
Bien entendu, la définition du bon seuil de confiance dépend de vos objectifs commerciaux. Voici une approche étape par étape pour déterminer les seuils optimaux :
- Analysez vos données: Commencez par évaluer la distribution des scores de confiance entre vos prédictions. Utilisez des outils de visualisation tels que des histogrammes pour voir comment les scores de confiance se regroupent.
- Etablir des seuils initiaux: par exemple, si 80 % de vos prédictions ont un score de confiance supérieur à 90 %, vous pouvez définir un seuil d'acceptation automatique à 90 %.
- Testez et itérez: Surveillez en permanence l'impact de l'ajustement des seuils sur les faux positifs et les faux négatifs. Par exemple, l'abaissement de votre seuil à 85 % pourrait permettre de résoudre davantage de problèmes mais pourrait augmenter la charge de travail des révisions manuelles.
L'impact des scores de confiance sur l'ensemble précision est significatif. Au cours de la phase d'entraînement, les modèles sont exposés à diverses données pour calibrer les résultats de confiance. L'utilisation de techniques telles que l'échantillonnage bootstrap permet d'affiner davantage les performances du modèle en estimant les intervalles de confiance ou en testant la robustesse par rapport à divers sous-ensembles de données.
Par exemple, une méthode robuste pour évaluer les scores de confiance consiste à tester les prédictions sur des échantillons invisibles et à évaluer l'alignement entre les scores de confiance et les résultats réels.
N'oubliez pas de consulter notre article sur création de produits d'IA!
La courbe de rappel de précision (courbe PR)
Pour choisir la meilleure valeur du seuil que vous souhaitez définir dans votre application, la méthode la plus courante consiste à tracer une courbe de mémoire et de précision (courbe PR).
Pour ce faire, vous allez calculer la précision et la mémoire de votre algorithme sur un jeu de données de test, pour de nombreuses valeurs de seuil différentes. Une fois que vous avez tous vos couples (pr, re), vous pouvez les tracer sur un graphique qui ressemble à :
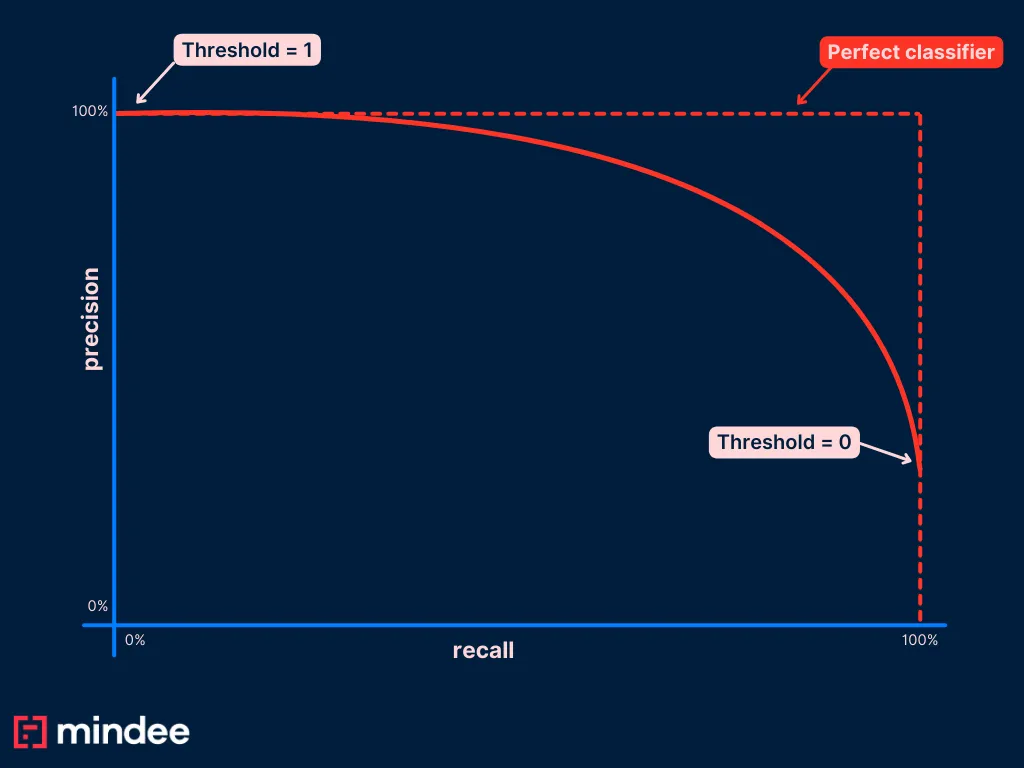
Les courbes PR commencent toujours par un point (r=0 ; p=1) par convention.
Une fois que vous avez cette courbe, vous pouvez facilement voir quel point de la courbe bleue convient le mieux à votre cas d'utilisation. Vous pouvez ensuite savoir quel est le seuil pour ce point et le définir dans votre candidature.
Comment tracer votre courbe de relations publiques ?
Tous les exemples précédents concernaient des problèmes de classification binaire où nos algorithmes ne peuvent prédire que « vrai » ou « faux ». Dans le monde réel, les cas d'utilisation sont un peu plus compliqués, mais toutes les métriques précédentes peuvent être généralisées.
Prenons un nouvel exemple : nous avons une OCR basée sur le machine learning qui extrait les données des factures. Cette OCR extrait un ensemble de données différentes (montant total, numéro de facture, date de facture...) ainsi que des scores de confiance pour chacune de ces prédictions.
Quel seuil devons-nous définir pour les prévisions de date de facturation ?
Ce problème n'est pas un problème de classification binaire, et pour répondre à cette question et tracer notre courbe PR, nous devons définir ce que sont une vraie valeur prédite et une valeur faussement prédite.
Toute la complexité réside ici dans la formulation des bonnes hypothèses qui nous permettront d'ajuster nos métriques de classification binaires : fp, tp, fn, tp
Voici nos hypothèses :
- Chaque facture de notre ensemble de données contient une date de facturation
- Notre OCR peut renvoyer une date ou une prédiction vide
Si, contrairement à #1, votre jeu de données de test contient des factures sans aucune date de facturation, je vous recommande vivement de les supprimer de votre ensemble de données et de terminer ce premier guide avant d'ajouter de la complexité. Cette hypothèse n'est évidemment pas vraie dans le monde réel, mais le cadre suivant serait beaucoup plus compliqué à décrire et à comprendre sans cela.
Définissons maintenant nos indicateurs :
- vrai positif: l'OCR a correctement extrait la date de facturation
- faux positif: l'OCR a extrait une date erronée
- vrai négatif: ce cas n'est pas possible car il y a toujours une date inscrite sur nos factures
- faux négatif: L'OCR n'a extrait aucune date de facture (c'est-à-dire une prédiction vide)
Avant de passer aux étapes permettant de tracer notre courbe PR, réfléchissons aux différences entre notre modèle et un problème de classification binaire.
Que signifie définir un seuil de 0 dans notre cas d'utilisation de l'OCR ? Cela signifie que nous n'allons rejeter aucune prédiction MAIS contrairement aux problèmes de classification binaire, cela ne signifie pas que nous allons prédire correctement toutes les valeurs positives. En effet, notre OCR peut prédire une date erronée.
Cela implique que nous n'atteindrons peut-être jamais un point de notre courbe où le rappel est égal à 1. Ce point est généralement atteint lorsque le seuil est réglé sur 0. Dans notre cas, ce seuil nous donnera la proportion de prévisions correctes dans l'ensemble de notre ensemble de données (n'oubliez pas qu'il n'y a pas de facture sans date de facturation).
Nous attendons alors à avoir ce type de courbe au final :
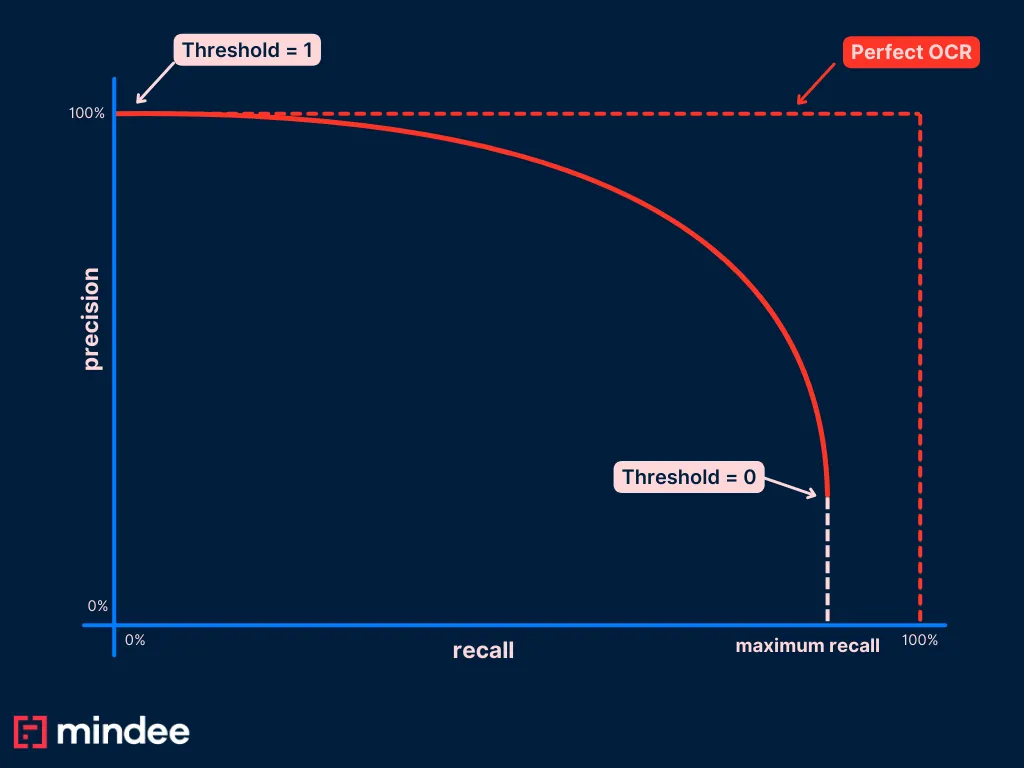
Nous sommes maintenant prêts à tracer notre courbe de relations publiques.
Étape 1 : exécutez l'OCR sur chaque facture de votre jeu de données de test et stockez les trois points de données suivants pour chacun
- La prédiction était-elle correcte ?
- Quel était le score de confiance de la prédiction ?
- La prédiction était-elle remplie d'une date (au lieu d'être « vide ») ?
Le résultat de cette première étape peut être un simple fichier .csv comme celui-ci :

{{cta-consideration-1= » /en cours /global-blog-elements «}}
Etape 2 : calcul du rappel et de la précision pour le seuil = 0
Nous devons maintenant calculer la précision et la rappeler pour threshold = 0.
C'est la partie la plus simple. Nous avons juste besoin de qualifier chacune de nos prédictions en tant que fp, tp ou fn comme il s'y trouve ne peut pas être un vrai négatif selon notre modélisation.

Fais le calcul. Dans l'exemple ci-dessus, nous avons :
- 8 vrais points positifs
- 5 faux positifs
- 3 faux négatifs
Dans notre premier exemple avec un seuil de 0., nous avons alors :
- Précision = 8/ (8+5) = 61 %
- Rappel = 8/ (8+3) = 72 %
Nous avons le premier point de notre courbe de relations publiques : (r = 0,72, p = 0,61)
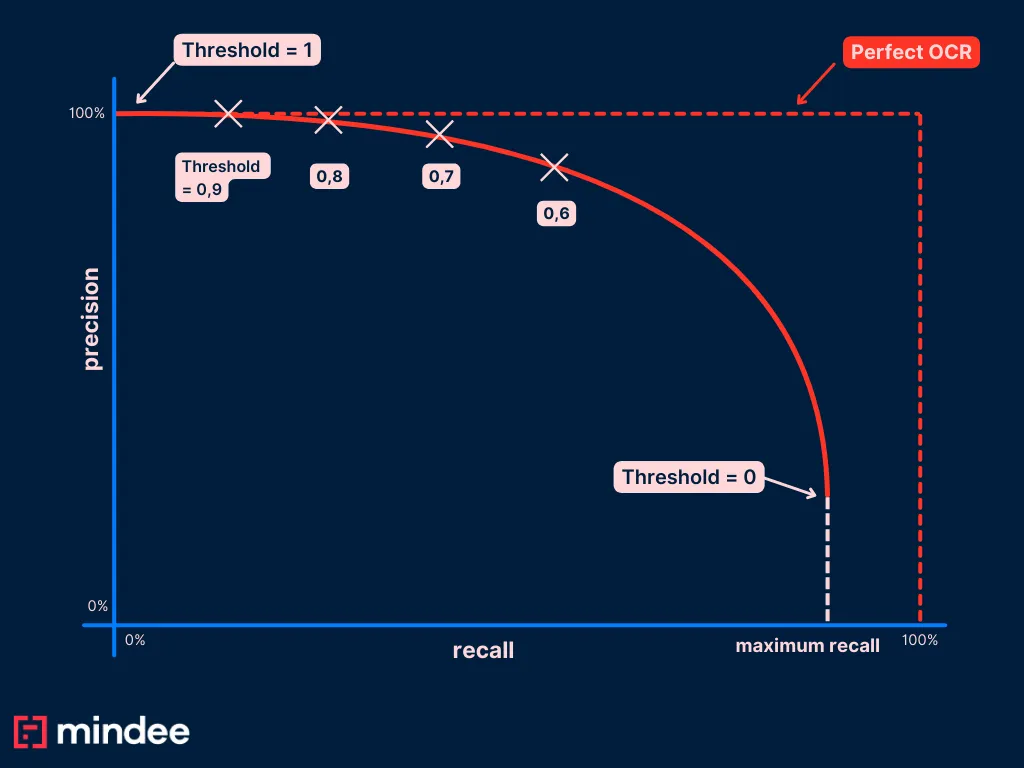
Étape 3 : Répète cette étape pour une valeur de seuil différente
Nous venons de calculer notre premier point, maintenant faisons-le pour différentes valeurs de seuil. We prendrons l'exemple d'une valeur de seuil = 0,9.
Comme nous l'avons mentionné ci-dessus, la définition d'un seuil de 0,9 signifie que nous considérons toutes les prévisions inférieures à 0,9 comme vides. En d'autres termes, nous devons tous les qualifier de valeurs faussement négatives (n'oubliez pas qu'il ne peut y avoir de vraies valeurs négatives).
Pour cela, vous pouvez ajouter une colonne dans notre fichier csv :

Dans le fichier CSV ci-dessus :
- Les lignes grises correspondent à des prévisions inférieures à notre seuil
- Les cases bleues correspondent aux prédictions selon lesquelles nous avons dû changer la qualification de FP ou TP à FN
Fais le calcul à nouveau.
Nous avons :
- 6 vrais points positifs
- 3 faux positifs
- 7 faux négatifs
Dans notre premier exemple avec un seuil de 0,9, nous avons alors :
- Précision = 6/ (6+3) = 66 %
- Rappel = 6/ (6+7) = 46 %
Il en résulte un nouveau point de notre courbe PR : (r = 0,46, p = 0,67)
Répète cette étape pour un ensemble de valeurs de seuil différentes, puis enregistre chaque point de données et le tour est joué !
Interpreter your public relations curve
Dans un monde idéal, vous avez beaucoup de données dans votre ensemble de tests et le modèle de machine learning que vous utilisez correspond parfaitement à la distribution des données. Dans ce cas, vous vous retrouvez avec une courbe PR avec une belle forme descendante à mesure que le rappel augmente, ce qui permet d'évaluer correctement votre score de confiance.
Mais une erreur courante est que vous n'avez peut-être pas beaucoup de données ou que vous n'utilisez pas le bon algorithme. Dans ce cas, la courbe PR que vous obtenez peut être informée et inexploitable en raison de la taille de vos données.
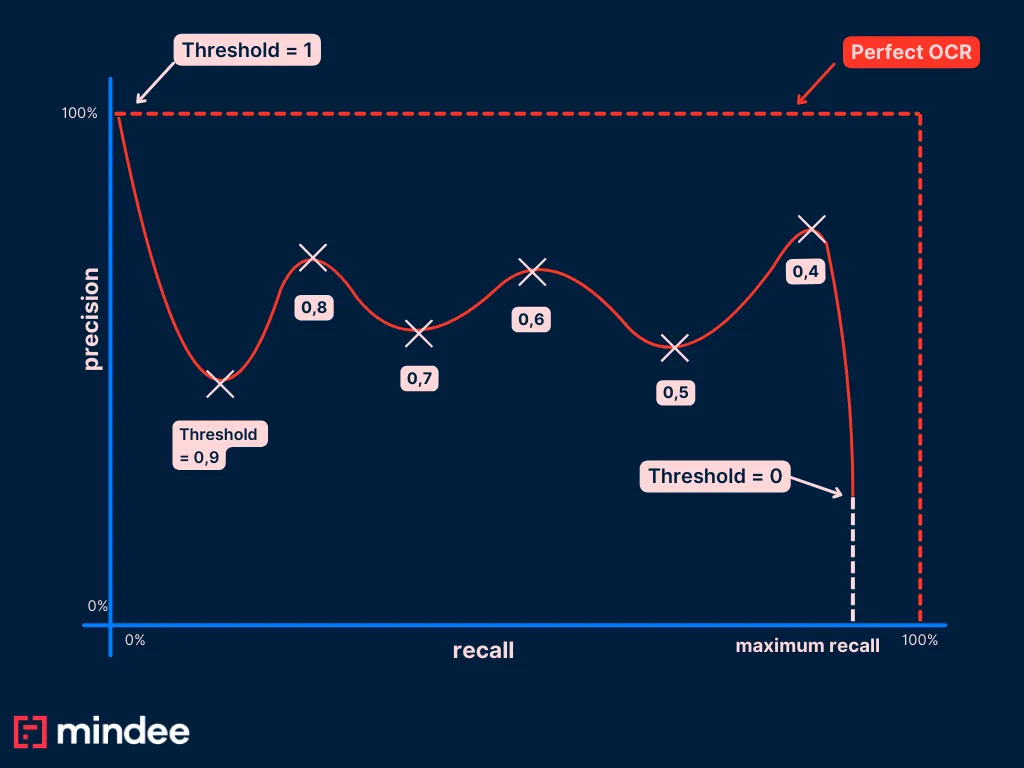
Voici un exemple de courbe de relations publiques dans le monde réel que nous avons tracée à Mindee sur un cas d'utilisation très similaire pour notre OCR de reçus sur le champ de date.
Notre ensemble de tests contient 10 000 données annotées, provenant d'environ 20 pays. La courbe PR du champ de date ressemble à ceci :
%252520(1).webp)
Les scores de confiance constituent un outil puissant pour affiner vos modèles d'apprentissage automatique et garantir qu'ils fournissent des informations précises et exploitables. En définissant des seuils avec soin et en surveillant en permanence les performances, vous pouvez maximiser la valeur de vos modèles en production.
Êtes-vous prêt à faire passer vos modèles de machine learning au niveau supérieur ? Découvrez la puissante API de traitement des documents de Mindee qui exploite les scores de confiance pour optimiser l'extraction des données. Ou consultez notre blog pour plus de conseils sur l'amélioration de vos flux de travail d'apprentissage automatique !
À propos
.svg)
.webp)
.webp)

.webp)