
.svg)
.webp)
Table of Contents
The snapshot
Remember gripping a pencil, sweating over a standardized test bubble sheet, terrified that a stray mark would ruin your score? That anxiety-inducing sheet was your first introduction to optical mark recognition. While we often associate it with school days, OMR has driven billion-dollar enterprise workflows for decades. Optical mark recognition revolutionized high-volume data collection by eliminating the bottleneck of manual data entry.
Today, modern computer vision algorithms transform it from a rigid, hardware-heavy process into a flexible, cloud-based software solution.
Define optical mark recognition (OMR)
Optical mark recognition (OMR) is the automated process of capturing human-marked data from document forms. Instead of reading text, the system specifically detects the presence or absence of a mark (like a filled bubble or a checkmark field) within predetermined spatial coordinates.
Imagine you configured a data pipeline for a national healthcare provider, stakeholders assume the scanning machine is reading the patient surveys. In reality, the algorithm simply flags marked zones. This binary approach allows organizations to extract structured data from multiple-choice questions and surveys instantly, drastically reducing manual data entry overhead.
.webp)
Trace the history of OMR technology
OMR evolved from heavy mechanical brush-sensing machines to sophisticated computer vision algorithms. In the early days, users needed specialized pencils with high graphite content because the earliest mark sense machines relied on electrical conductivity. Companies like IBM and NCS Pearson, Inc. dominated the early marketplace for educational testing. They successfully replaced mechanical brushes with optical light-sensing hardware, an era cemented by milestones like US Patent 2,944,734. We have moved far beyond these monolithic machines, but the core logic of spatial mark detection remains the absolute foundation of modern labeled OMR.
Explain the mechanics of OMR scanners and software
Traditional OMR relies on specialized scanners analyzing light reflection to detect marks, while modern software counts pixels. The mechanical process is remarkably straightforward. A document feeder pushes a machine-readable form through an imaging scanner. The scanner shines a light onto the plain paper and measures the reflected light. Dark marks absorb light, creating stark contrast differences.
The processing software generates a bitonal image (strictly black and white) and runs a mark recognition algorithm over predefined spatial zones. If the pixel density in a specific zone crosses a predetermined threshold, the system registers a filled bubble or checkbox.

Compare OMR with OCR and ICR technologies
OMR detects marks, OCR reads machine-printed text, and ICR interprets human handwriting. Clients frequently confuse these recognition engines. Let us define these concepts in explicit terms:
- OMR (Optical Mark Recognition): Detects binary marks (filled or empty). It requires the lowest processing power and delivers the highest accuracy.
- OCR (Optical Character Recognition): Converts typed images into machine-encoded text.
- ICR (Intelligent Character Recognition): A subset of OCR trained to decipher unpredictable human handwriting.
While OMR is unrivaled for sheer speed in binary data collection, it is entirely useless if you need to extract an email address or a handwritten name. Modern forms processing solves this limitation by layering all three technologies via REST APIs.
{{cta-awareness-1="/in-progress/global-blog-elements"}}
Review core applications and industry use cases
Organizations deploy OMR wherever high-volume, structured data collection demands absolute certainty. Skeptics often argue that digital web forms have rendered physical documents obsolete. However, large demographic segments still rely on physical paper, and stringent regulatory frameworks demand physical audit trails.
Election ballot counting remains the most critical application worldwide, requiring undeniable physical proof alongside rapid digital tallying. Beyond elections, we see massive daily volume relying on OMR for standardized testing, medical patient intake forms, and large-scale demographic survey forms.
Assess the advantages and limitations of OMR
OMR drastically cuts operational costs and error rates, but rigid form requirements limit its flexibility. The primary advantage is throughput. You can process tens of thousands of multiple-choice tests per hour with a near-zero error rate. The time and cost savings over manual data entry are immense.
The fatal flaw lies in structural variation intolerance. Missing data spikes the moment a user folds the page, uses the wrong ink color, or places a stray mark near a checkmark field. The system demands perfection from both the printer and the user.

Design effective machine-readable forms
Successful OMR extraction requires strict adherence to precise form design specifications. You cannot print a standard text document and expect a scanner to parse it. The layout must be surgically precise.
Registration marks (solid black squares or circles located in the corners of the page) tell the scanner how to orient the document. We use drop-out colors (usually red or light blue) for the background template. The scanner ignores these colors, seeing only the black graphite marks. You need specialized OMR fonts and a rigid precision scale to ensure flawless template-to-form position comparison.
Implement OMR workflows successfully
Deploying OMR requires perfectly aligning scanner hardware capabilities with rigorous quality control measures. When I managed a nationwide census project, I learned the hard way that even perfect form design specifications fail if your scanner specifications are inadequate.
If you utilize preprinted forms for labeled OMR, you must evaluate specialized scanners. A robust document feeder is mandatory to prevent jams when processing thousands of pages. The scanner hardware must integrate flawlessly with your software's mark recognition algorithm. This ensures the template-to-form position comparison remains accurate across every single omr sheet.
Ultimately, your data processing capabilities rely entirely on the quality control measures you implement to catch feeding errors and misalignments before they corrupt your database.
Evaluate modern OMR software and solutions
The market offers diverse OMR technology, shifting rapidly from legacy commercial software to flexible cloud-based platforms. Historically, organizations relied on heavy, localized form processing tools like Remark Office OMR and Remark Test Grading. While highly effective, these required significant upfront investment.
{{cta-consideration-1="/in-progress/global-blog-elements"}}
Today, cloud-based OMR platforms and specialized solutions like OCR.space OMR technology dominate the landscape. Developers can leverage a standard image scanner and extract check-box values and radio button values directly from a plain paper OMR survey form. Furthermore, modern mobile OMR features allow field workers to capture data via smartphones, eliminating the delay of batch scanning. From parsing complex mail markup to real-time surveys, the software ecosystem now prioritizes agility over rigid hardware dependencies.
Transition to modern API and cloud-based solutions
Modern cloud-based OMR platforms and REST APIs eliminate the need for expensive, specialized scanner hardware. In the past, deploying an OMR solution meant buying a $10,000 specialized scanner.
Today, computer vision algorithms run in the cloud, processing smartphone photos and plain paper OMR survey forms effortlessly. This shift to software drastically alters the developer landscape. For example, if you are processing a mixed batch of documents containing patient intake surveys and medical invoices, you can use an intelligent routing engine.
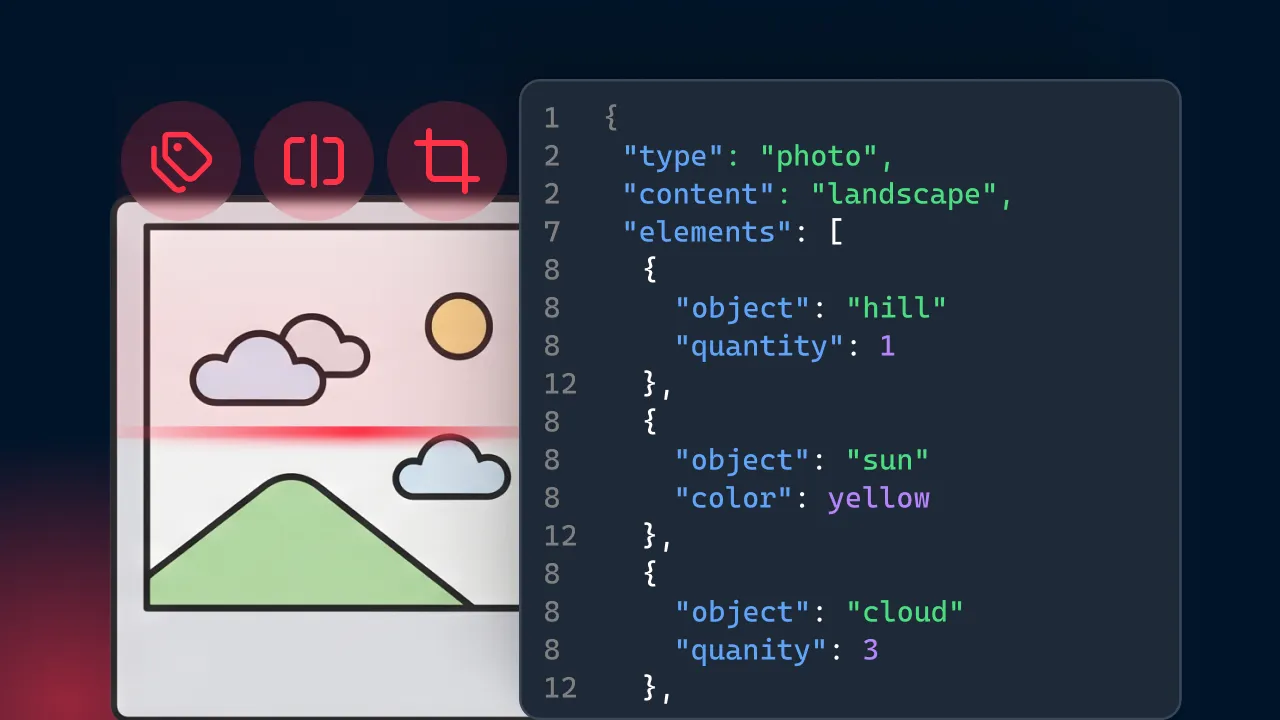
Mindee’s Classify tool analyzes incoming files and automatically categorizes them by type. This allows you to sort documents instantly and route them to the correct extraction pipeline. If these documents arrive combined in one massive PDF, you can deploy a Split endpoint to separate the individual forms before processing. In scenarios where multiple survey cards are photographed on a single desk, a Crop feature isolates each distinct document.
.webp)
Once routed, extracting the data does not require a dedicated OMR scanner. You can extract your data automatically by creating a custom extraction model on Mindee. Because the API provides the exact X/Y geometric coordinates of where that text lives on the page, developers can map check-box values directly to database schemas. Furthermore, the API gives a reliability rating for every extracted field. This lets developers automatically push data to their database when the AI is certain, while safely routing confusing or blurry documents to a human for manual review.
{{cta-conversion-1="/in-progress/global-blog-elements"}}
Final thoughts
OMR fundamentally shifted how we handle high-volume data collection, evolving from rigid hardware constraints to flexible software APIs. While the classic bubble sheet remains a nostalgic artifact, the spatial detection technology powering it seamlessly integrated into modern computer vision pipelines.
Integrating intelligent classification, AI extraction, and OMR into a single architecture provides a comprehensive, fail-safe solution for modern forms processing. Compared to the massive capital expenditure of traditional scanners, scalable cloud pricing models allow teams to innovate faster. You can sign up today to build your own extraction pipeline and leave the rigid hardware in the past.
About
.svg)
.webp)
.webp)
.webp)