
.svg)
.webp)
Table of Contents
The snapshot
Manual data entry carries a baseline error rate between 1% and 5%. That sounds negligible until you map it onto an enterprise scale. If your accounting department processes 10,000 invoices a month, that equates to 100 corrupted database entries bleeding revenue (at least), triggering compliance audits, and wasting hundreds of hours in reconciliation. Automated data capture is the non-negotiable foundation of modern operations.
By replacing human keystrokes with intelligent document processing, businesses scale their data ingestion pipelines infinitely while driving error rates close to zero. In this guide, we break down the core technologies powering modern extraction, map out how to overcome implementation hurdles, and explain why upgrading your extraction pipeline is the highest-ROI technical decision you can make this year.
Ditch manual entry for automated data capture systems
Automated data capture systems extract information from physical and digital sources without human keystrokes, fundamentally transforming document ingestion. If you ever had architected backend document pipelines, the starkest difference between legacy manual workflows and modern automation is flexibility. Manual data capture relies on rigid templates and manual zone definitions.
If a vendor updates their invoice format and shifts a total down by two pixels, a template-based system breaks immediately.
Automated data capture, driven by intelligent recognition, does not care about coordinates. It understands the document contextually, allowing developers to pull data from unstandardized, unstructured documents just as easily as perfectly formatted digital forms.
Understand the core technologies powering data extraction
Modern capture relies on a sophisticated stack, from basic optical character recognition (OCR) to artificial intelligence (AI), to interpret complex documents. Standard OCR technology is a blunt instrument: it reads pixels and outputs flat text. Intelligent document processing (IDP) goes further by applying machine learning to understand the context of those pixels, while intelligent character recognition (ICR) translates complex handwriting into structured text.
To automatically pull structured data like totals, taxes, dates, names, and table line items from unstructured documents like PDFs or photos, you need an AI-powered document parsing platform.
Mindee provides exactly this through Extract, its core product. Instead of building parsing logic from scratch, developers leverage Mindee's "off-the-shelf" AI models for common documents like invoices, receipts, ID cards, and passports. If your business handles highly proprietary paperwork, you can use the custom API builder to train your own models specifically for your company's documents.
{{cta-consideration-1="/in-progress/global-blog-elements"}}
Cut costs and boost accuracy with automation
Deploying automated capture slashes operational costs, reduces human error, and removes soul-crushing repetitive tasks for employees.
When you replace manual data entry with AI machine learning, the front-end costs of implementation are rapidly dwarfed by the long-term savings in software maintenance and human labor. More importantly, automated capture enforces rigorous data validation rules that guarantee the fidelity of your ingested documents.
For enterprise teams, automation also secures compliance. Navigating strict privacy laws like GDPR requires absolute control over document processing. Higher tiers of modern data capture platforms allow you to force data processing localization, ensuring your documents are processed only in specific geographic regions (e.g., only in Europe) and enforcing strict data retention policies.
.webp)
Calculate costs and considerations for implementation
Implementing an OCR data capture system requires mapping out upfront investments against long-term savings, factoring in everything from training to cloud infrastructure.
While the ROI is undeniable, leaders must account for front-end costs. This includes initial software validation and testing to ensure the system accurately handles complex table extraction and tricky handwriting recognition within specific workflows. Ongoing expenses typically include software maintenance costs and necessary training costs for your team to adapt to the new tool.
To optimize budgets, modern solutions rely on robust cloud processing functionalities rather than expensive on-premise hardware.
Furthermore, by evaluating your monthly document volume, you can leverage flexible pay-as-you-go pricing models. For instance, Mindee uses a system where 1 credit equals 1 page processed, ensuring you only pay for the exact volume you ingest.
{{cta-awareness-1="/in-progress/global-blog-elements"}}
Anticipate and overcome implementation challenges
Automated data capture presents real hurdles, such as handwriting recognition limits and unstandardized formats, requiring strategic foresight.
A common objection to automation is what happens when the AI encounters an entirely novel, messy document. Building a resilient pipeline means implementing a human-in-the-loop fallback. A robust API gives a reliability rating for every extracted field via confidence scores. This lets developers automatically push data to their database when the AI is certain, while safely routing confusing or blurry documents to a human for manual review.
.webp)
When manual review is necessary, UI features like polygons and bounding boxes make verification instant. The API provides the exact X/Y geometric coordinates of where text lives on the page, allowing users to click a piece of data and see exactly where it was pulled from on the original image. Furthermore, with RAG (Continuous Learning), instead of fully retraining an AI model when it struggles with a new document layout, you just correct the error once. The system remembers this correction and instantly applies it to similar documents in the future, getting smarter on the fly.
.webp)
Leverage automated data capture in high-volume industries
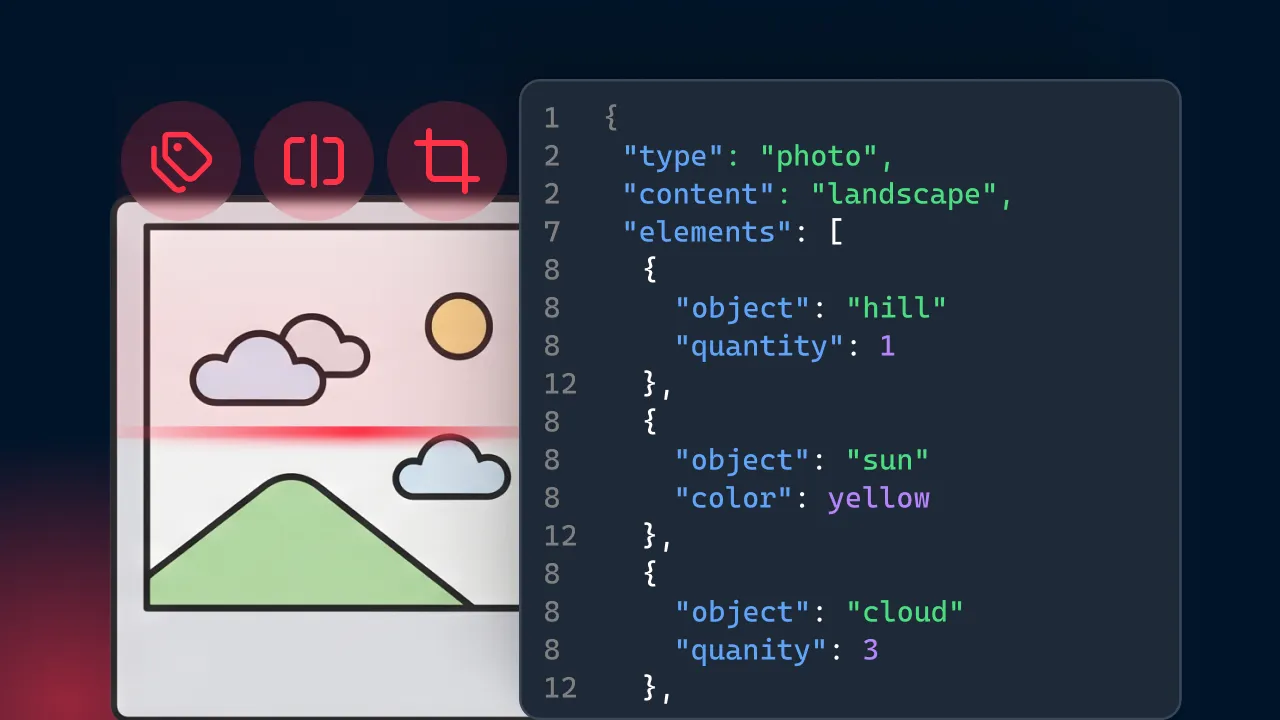
High-volume sectors like finance, insurance, and human resources rely on automated data capture to keep mission-critical workflows moving.Consider a typical accounting workflow: an inbox receives a 50-page PDF containing a whole day's worth of mixed mail. Manually separating this is tedious. Tools like Mindee's Split handle this automatically; the AI detects where each individual document begins and ends, automatically splitting the large file into logical, separate documents.
Once split, an intelligent routing engine analyzes incoming files and automatically categorizes them by type via tools like Classify. This allows businesses to sort documents instantly and route them to the correct extraction pipeline. If an HR employee photographs three receipts placed on a desk together, tools like Crop detect each distinct document, isolate it, and crop it into a separate file so data isn't mixed up.
Evaluate and select the right automated data capture solution
Choosing the ideal data capture technology requires evaluating interface usability, handling of monthly document volume, and downstream integration capabilities.Do not settle for tools that trap you in isolated ecosystems. The best solutions offer official SDKs (client libraries) in languages like Python, Node.js, Java, .NET (C#), Ruby, and PHP. This provides type safety, built-in error handling, and autocompletion without writing boilerplate HTTP code. If you lack dedicated engineering resources, ensure your platform connects to no-code tools like Zapier, N8N, and Make.
For heavy workloads and multi-page documents, favor architectures that support webhooks. You simply send the document and tell the API to ping a specific URL on your server when done; the AI then actively pushes the JSON results back to your system, keeping your application fast. Finally, align the pricing with your monthly document volume. Mindee scales from a Starter tier (€44 / month for 500 credits) to a Pro tier (€179 / month for 2,500 credits and continuous learning features) up to Business and Custom Enterprise levels.
{{cta-conversion-1="/in-progress/global-blog-elements"}}
Prepare for future trends in automated data capture
The next evolution of data-capturing technologies will move beyond static documents, integrating dynamic inputs and autonomous decision-making to handle complex workflows.
Today, AI-powered data capture systems driven by advanced AI/ML and machine learning are already mastering both structured data and semi-structured use cases.
However, the future of data capture technology is heavily multimodal. We anticipate a surge in voice recognition technology and voice capture, allowing field workers to dictate data that is automatically parsed and structured alongside physical documents. As model-trained capture becomes more sophisticated, it will seamlessly integrate with robotic process automation (RPA), enabling systems to not just extract data, but to autonomously execute multi-step business actions based on that intelligence.
Final thoughts
Automated data capture is no longer a futuristic luxury; it is the baseline requirement for maintaining data integrity and operational velocity. By moving away from manual zone definitions and embracing AI-driven extraction, businesses eliminate human error and scale their ingestion pipelines effortlessly. As machine learning models and robotic process automation (RPA) continue to converge, the companies that lay a strong, automated foundation today will be the ones positioned to deploy the fully autonomous workflows of tomorrow. Ready to transform your document workflow? Sign up for Mindee today.
About
.svg)
.webp)
.webp)
.webp)