
.svg)


Sommaire
Les files d'attente de multi-processing len Python permettent à plusieurs processus d'échanger des objets entre eux en toute sécurité. Cependant, ces files d'attente peuvent devenir lentes lorsque des objets volumineux sont partagés entre des processus. Cela peut être le cas pour plusieurs raisons :
- Décapage et décapage : Les objets placés dans des files d'attente multitraitement sont décapés, transférés sur la file d'attente, puis dédécapés. Les étapes de décapage et de dédécapage entraînent des frais supplémentaires, qui peuvent être importants pour les objets volumineux. En effet, les objets volumineux nécessitent davantage de données pour être décapées et transférées, et l'étape de dédécapage nécessite la reconstruction de l'objet entier.
- Limites du GIL : Le Global Interpreter Lock (GIL) empêche plusieurs threads natifs d'exécuter des byte-codes Python à la fois. Ce verrouillage est nécessaire principalement parce que la gestion de la mémoire de Python n'est pas sûre pour les threads. Étant donné que les files d'attente multitraitement utilisent des verrous pour transférer des objets en toute sécurité entre les processus, le GIL peut limiter les performances lors du transfert d'objets volumineux nécessitant l'acquisition du verrou pendant de longues périodes.
- Copie de mémoire : Les files d'attente multitraitement créent des copies des objets lorsqu'ils sont transférés d'un processus à l'autre. Pour les objets volumineux, la création de copies peut être très coûteuse en termes de temps et de mémoire.
Pour améliorer les performances, il est préférable d'éviter autant que possible de partager des objets volumineux sur des files d'attente multitraitements.
Si nécessaire, une approche consiste à partager des objets de mémoire à l'aide du types de cc partagés et multiprocesseurs module au lieu du décapage, ce qui évite les frais liés au décapage et au dédécapage.
Expérience de multi-processing mettant en évidence le problème
Voici l'expérience en Python. La seule différence entre nos deux expériences est la taille des objets partagés dans la file d'attente. Tous les calculs intensifs (la multiplication matricielle) sont exactement les mêmes, quel que soit ce que nous mettons dans la file d'attente.
Cela s'exécute sur mon ordinateur en 7 secondes environ. Comme nous pouvons le voir, l'état de chaque sous-processus est R, ce qui signifie qu'il est en cours d'exécution.
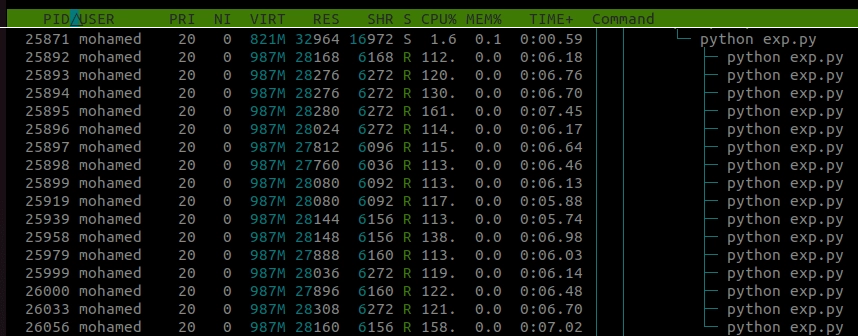
Mettons plutôt un tableau numpy lourd dans la file d'attente.
Remplacez la ligne où nous avons mis un 1 dans la file d'attente par :
Cela s'exécute sur mon ordinateur en 145 secondes environ. Il est plus de 20 fois plus lent même si les calculs sont exactement les mêmes. Comme nous pouvons le voir, l'état de chaque sous-processus est S, ce qui signifie qu'il est en veille.
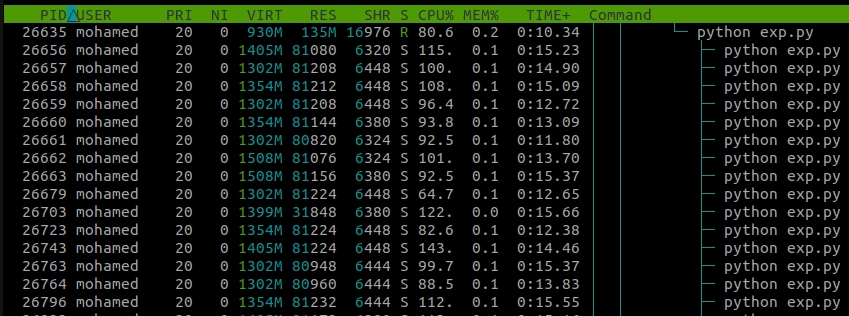
Écrire directement sur le disque dur pour communiquer entre les processus au lieu d'utiliser des files d'attente multitraitement en Python présente des avantages et des inconvénients :
Avantages :
- Éviter le décapage et le dédécapage en hauteur pour les gros objets. L'écriture sur disque permet d'éviter de sérialiser les objets.
- Éviter la copie de mémoire qui se produit avec les files d'attente. Les objets sont écrits une seule fois sur le disque au lieu d'être copiés dans la file d'attente.
- Performances d'E/S potentiellement plus rapides en écrivant de manière séquentielle sur le disque au lieu de l'ajouter à une file d'attente.
Inconvénients :
- La synchronisation entre les processus doit être gérée manuellement. Les files d'attente fournissent une implémentation sûre pour l'échange d'objets entre les processus.
- La gestion des erreurs est plus complexe. L'implémentation de la file d'attente gère les erreurs qui peuvent survenir lors des transferts d'objets. Cette logique devrait être réimplémentée.
- Les objets sur le disque ne sont pas accessibles depuis Python et doivent être chargés avant utilisation. Les objets de la file d'attente restent en mémoire.
À propos
.svg)
.webp)
.webp)

.webp)