
.svg)


Sommaire
L' aperçu
Un système de RAG est un type de modèle de machine learning qui améliore la sortie d'un modèle de langage en intégrant des sources de données externes. Essentiellement, il extrait les informations pertinentes d'une base de données et utilise ces informations pour générer des réponses plus précises et plus éclairées.
Dans cet article, nous aborderons les subtilités de la construction d'un système de Retrieval Augmented Generation (RAG). Nous allons clarifier les concepts fondamentaux, composants architecturaux, et stratégies de mise en œuvre impliqués dans la construction d'un tel système.
Grâce à une exploration complète des principes sous-jacents et des considérations pratiques, nous visons à vous fournir les connaissances et les outils nécessaires pour développer votre propre système RAG efficace !
Qu'est-ce que le RAG (Retrieval Augmented Generation) ?
RAG est un framework qui combine des systèmes de recherche d'informations (IR) avec n'importe quel modèle génératif (mais généralement de grands modèles de langage mieux connus sous le nom de LLM) pour améliorer la qualité et la précision du texte généré.
Comment fonctionne le RAG
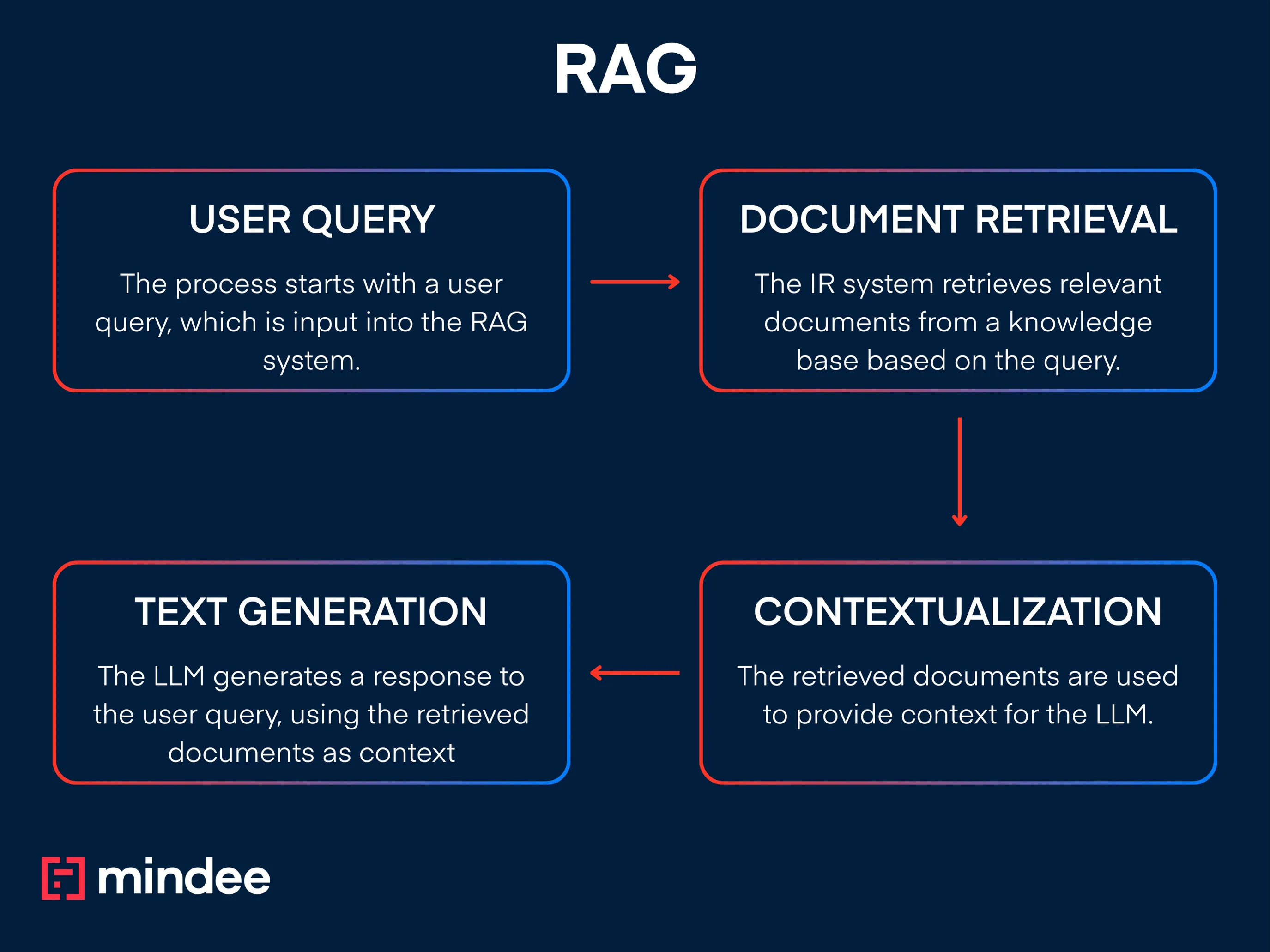
Applications et cas d'utilisation
Les systèmes RAG sont particulièrement utiles dans les scénarios qui exigent à la fois précision et compréhension du contexte.
Par exemple, dans le domaine du service client, un système RAG peut récupérer les interactions précédentes avec les clients et les détails des produits pour offrir une assistance personnalisée.
Dans le domaine de la santé, il peut extraire de la littérature médicale pertinente pour aider à établir un diagnostic précis.
Les applications potentielles sont vastes et concernent divers secteurs, faisant des systèmes RAG un outil polyvalent pour améliorer les interactions pilotées par les données.
Principaux composants d'un système de RAG
Pour créer un système de RAG, vous devez comprendre ses deux composantes principales :
- Retriever: Ce composant est chargé de récupérer les documents ou les données pertinents à partir d'un vaste corpus en fonction de la requête d'entrée.
- Générateur: Une fois les données pertinentes récupérées, le générateur les utilise pour produire une réponse cohérente et adaptée au contexte.
Intégration de composants
L'intégration du retriever et du générateur est une étape cruciale dans la construction d'un système RAG. Cette intégration garantit une bonne communication entre les deux composants, ce qui permet de récupérer des données en temps réel et de générer des réponses.
Une intégration efficace implique de garantir la compatibilité entre les formats de données utilisés par le récupérateur et les exigences d'entrée du générateur, ainsi que d'établir un flux de travail fluide pour le traitement des requêtes.
Étapes pour créer votre propre système de RAG
🧰 Étape 1 : Configuration de l'environnement
Tout d'abord, assurez-vous que votre environnement de développement est prêt. Vous aurez besoin d'un langage de programmation qui prend en charge les bibliothèques d'apprentissage automatique. Python est un choix populaire en raison de ses bibliothèques étendues telles que TensorFlow et PyTorch.
Choisir les bons outils
La sélection des outils et des bibliothèques appropriés est cruciale pour créer un système RAG efficace.
L'écosystème robuste de Python propose de nombreuses bibliothèques comme TensorFlow pour le deep learning, PyTorch pour la création flexible de réseaux neuronaux, et scikit-learn pour les opérations d'apprentissage automatique de base. Ces outils constituent la base sur laquelle repose le système RAG.
Installation des bibliothèques nécessaires
Commencez par installer les bibliothèques Python essentielles.
Exécutez la commande suivante pour configurer votre environnement :
ensembles de données pip install Torch Transformers
Ces bibliothèques vous fourniront les fonctionnalités nécessaires pour créer à la fois les composants de récupération et de génération du système RAG.
Configuration de l'environnement de développement
Assurez-vous que votre environnement de développement est configuré pour gérer les exigences de calcul liées à la formation et à l'exécution de modèles d'apprentissage automatique.
Cela peut impliquer configurer des environnements virtuels, garantir la compatibilité avec votre matériel et optimiser les paramètres de performance.
Un environnement bien configuré rationalisera le processus de développement et réduira les problèmes potentiels.
📦 Étape 2 : Préparation des données
Le succès d'un système RAG dépend largement de la qualité et de la pertinence des données qu'il peut récupérer. Vous avez besoin d'un ensemble de données bien structuré auquel le retriever peut accéder. Cet ensemble de données doit être complet et pertinent pour le domaine de votre application.
Sourcing de données de qualité
Commencez par identifier et rechercher des ensembles de données qui correspondent au domaine de votre application. Des ressources telles que Hugging Face offrent un large éventail de données prétraitées adaptées à diverses applications.
Assurez-vous que les ensembles de données que vous choisissez sont complets et à jour, car cela aura un impact direct sur les performances du système.
Structuration et prétraitement des données
Une fois obtenues, structurez et prétraitez vos données pour vous assurer qu'elles sont prêtes à être récupérées. Cela implique le nettoyage des données, la suppression des doublons et leur organisation dans un format qui facilite une recherche efficace. Le prétraitement est une étape cruciale qui améliore la précision du retriever en garantissant qu'il fonctionne sur des données pertinentes et de haute qualité.
Garantir la pertinence des données
Évaluez et mettez à jour en permanence vos ensembles de données pour maintenir leur pertinence. La nature dynamique des informations signifie que les ensembles de données peuvent rapidement devenir obsolètes.
Des mises à jour régulières garantissent que le système RAG fournit des réponses précises et rapides, améliorant ainsi la satisfaction des utilisateurs et la fiabilité du système.
{{cta-conversion-1= » /en cours/éléments de blog mondiaux "}}
🧲 Étape 3 : Construire le retriever
Le travail du retriever consiste à trouver les documents pertinents pour la requête. Vous pouvez utiliser des techniques telles que le BM25 ou des récupérateurs neuronaux plus avancés.
Pour simplifier, commençons par vectorisateur TF-IDF de base.
Implémentation d'un retriever de base
Commencez par implémenter un vectorisateur TF-IDF simple pour comprendre le processus de récupération. Cette approche utilise la fréquence des termes et la fréquence inverse des documents pour classer les documents en fonction de leur pertinence par rapport à la requête d'entrée.
Bien que cet exemple soit simple, il fournit une base solide pour comprendre les mécanismes de récupération.
L'extrait de code suivant montre comment importer les modules nécessaires depuis scikit-learn :
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
En outre, vous pouvez calculer la matrice TF-IDF pour un ensemble de documents. Par exemple :
# Example documents
documents = ["Document 1 text", "Document 2 text", "Document 3 text"]
# Create and fit the TF-IDF vectorizer on the documents
vectorizer = TfidfVectorizer().fit_transform(documents)
# Convert the sparse matrix to a dense array
vectors = vectorizer.toarray()
Cet extrait définit une liste de documents, applique le vectorisateur TF-IDF pour apprendre le vocabulaire et calculer la matrice des termes du document, et convertit enfin la matrice creuse en un tableau dense pour faciliter l'analyse.
Exploration des techniques de récupération avancées
Une fois à l'aise avec la récupération de base, explorez des techniques plus avancées telles que le BM25 ou les récupérateurs basés sur des réseaux neuronaux. Ces méthodes offrent une précision et une efficacité accrues en tirant parti d'informations plus approfondies sur les données.
Testez différents modèles pour trouver celui qui convient le mieux aux besoins de votre application !
Évaluation des performances du retriever
Évaluez régulièrement les performances de votre retriever à l'aide de mesures telles que précision, rappel et score F1.
Ces indicateurs permettent d'identifier les domaines à améliorer et de garantir que le retriever fournit constamment des résultats pertinents.
Le réglage et l'itération sont essentiels pour optimiser les performances du retriever !
🧠 Étape 4 : Développement du générateur
Une fois que le récupérateur a identifié les documents pertinents, le générateur crée la réponse finale.
Configuration du générateur
Commencez par mettre en place un modèle de langage capable de générer des réponses cohérentes.
Les choix les plus populaires incluent le GPT-3 ou les modèles disponibles via Transformateurs Hugging Face bibliothèque.
Pour vous assurer que le modèle est correctement configuré pour gérer les données entrées depuis le système de récupération, vous pouvez initialiser un pipeline de génération de texte comme suit :
from transformers import pipeline
# Configure the text-generation model using a specific model
generator = pipeline("text-generation", model="gpt-3")
Élaboration de réponses contextuelles
Tirez parti du générateur pour élaborer des réponses à la fois informatives et adaptées au contexte. Cela implique introduction des documents récupérés dans le modèle et en spécifiant des paramètres tels que la longueur de réponse et la créativité.
Ajustez ces paramètres pour trouver un équilibre entre information et engagement :
# Combine the relevant documents into a single context string
context = " ".join([documents[i] for i in relevant_docs])
# Generate a response using the configured generator
response = generator(context, max_length=150, num_return_sequences=1)
# Print the generated response
print(response)
Améliorer les capacités génératives
Testez différentes configurations et paramètres de modèles pour améliorer les capacités du générateur.
Explorez des options telles que réglage des paramètres de température, utilisation de la recherche par faisceau ou intégration de données d'entraînement supplémentaires. Ces améliorations peuvent améliorer de manière significative la qualité et la pertinence des réponses générées.
🔗 Étape 5 : Intégrer et tester le système
Une fois les deux composants en place, intégrez-les pour former votre système RAG complet.
Testez le système à l'aide de différentes requêtes pour s'assurer qu'il récupère et génère des réponses avec précision.
Établissement de protocoles d'intégration
Développez des protocoles pour intégrer le récupérateur et le générateur dans un système cohésif. Cela implique de garantir la compatibilité des données et d'établir un flux de travail efficace pour le traitement des requêtes.
Une intégration efficace est cruciale pour fonctionnement fluide et génération de réponse précise.
Réalisation de tests complets
Effectuez des tests approfondis pour évaluer les performances du système dans différents scénarios. Utilisez un ensemble varié de requêtes pour tester la capacité du système à récupérer des données pertinentes et à générer des réponses appropriées.
Les tests aident identifier les problèmes potentiels et les domaines à améliorer.
Raffinement itératif
Affinez le système de manière itérative en fonction des commentaires des tests. Cela implique de modifier les paramètres, de résoudre tous les problèmes identifiés et de surveiller en permanence les performances.
Raffinement itératif garantit la robustesse du système RAG et capable de fournir des réponses de haute qualité.
🛠️ Étape 6 : Ajustement et optimisation
Pour améliorer les performances, pensez à affiner à la fois le récupérateur et le générateur de votre ensemble de données spécifique. Cela implique d'ajuster les paramètres du modèle et de s'entraîner à l'aide de données spécifiques au domaine pour améliorer la précision et la pertinence.
Comprendre les techniques de réglage
Familiarisez-vous avec les techniques de réglage précises applicables aux composants de récupération et de génération. Cela peut impliquer apprentissage supervisé pour les récupérateurs et apprentissage par transfert pour les générateurs.
La compréhension de ces techniques est cruciale pour optimiser les performances des modèles.
Mise en œuvre d'une formation spécifique à un domaine
Participez à une formation spécifique au domaine pour adapter le système RAG aux besoins de votre application. Cela implique en utilisant des ensembles de données et des modèles d'entraînement spécialisés pour identifier et hiérarchiser les informations pertinentes au domaine.
La formation spécifique au domaine améliore la capacité du système à fournir des réponses précises et pertinentes.
Suivi et évaluation des améliorations
Surveillez en permanence les effets des ajustements et évaluez les améliorations à l'aide de mesures de performance. Suivez l'évolution de la précision, de la qualité des réponses et de la satisfaction des utilisateurs pour évaluer l'efficacité de vos efforts d'optimisation.
Une évaluation régulière garantit des performances durables du système.
{{cta-consideration-1= » /in-progress /global-blog-elements «}}
🚀 Étape 7 : Déploiement de votre système RAG
Une fois que vous êtes satisfait des performances, déployez votre système RAG. Cela peut impliquer la configuration d'un serveur Web ou l'intégration du système dans une application existante.
Préparation au déploiement
Préparez votre système pour le déploiement en tenant compte des considérations techniques et logistiques. Cela inclut de s'assurer évolutivité, mise en place de protocoles de sécurité et configuration des environnements de serveurs. Une préparation adéquate minimise les problèmes de déploiement potentiels et garantit une transition en douceur.
Choix des plateformes de déploiement
Sélectionnez les plateformes appropriées pour déploiement de votre système RAG. Les options vont des services basés sur le cloud tels qu'AWS ou Azure aux solutions sur site. Prenez en compte des facteurs tels que le coût, l'évolutivité et la facilité d'intégration lors du choix d'une plateforme de déploiement.
En résumé, même si cela peut sembler complexe au départ, décomposer les construction d'un système RAG en étapes gérables le rend réalisable. En suivant ce guide, vous pouvez créer un système qui améliore les capacités des modèles linguistiques traditionnels, en fournissant des réponses plus informées et tenant compte du contexte.
N'oubliez pas que la clé du succès d'un système RAG réside dans la qualité de vos données et la précision des composants du récupérateur et du générateur. Avec de la pratique et des ajustements, vous pouvez créez un système robuste qui répond aux besoins spécifiques de vos applications !
À propos
.svg)

.webp)
.webp)

.webp)