
.svg)

Table of Contents
The snapshot
Amazon Textract popularized cloud-based OCR (Optical Character Recognition: the fundamental technology used to read text from images). However, pushing chaotic document layouts like deeply nested invoice tables through a legacy cloud API introduces severe friction. You send an image to the cloud and subsequently drown in thousands of lines of custom validation code to make the structured JSON (JavaScript Object Notation: the standard lightweight data-interchange format) usable.
Scaling document processing demands a solution balancing pinpoint accuracy, developer-friendly integration, and predictable costs. We will break down the leading Textract alternatives to help you choose the optimal tool for your engineering stack.
Evaluate top Amazon Textract competitors for your stack
Google Document AI, Azure Document Intelligence, and specialized API platforms offer distinct architectural advantages over Textract. Ultimately, your choice depends strictly on whether your organization prioritizes vendor consolidation or agile data extraction.
When engineering leads evaluate cloud providers, architecture dictates the decision, because migrating between massive ecosystems rarely solves underlying extraction bottlenecks.
Azure Document Intelligence
Microsoft enforces robust enterprise compliance and delivers highly structured JSON data. It excels in strictly governed environments. However, the custom model training proves rigid when confronting highly variable vendor documents, requiring significant overhead to maintain as layouts evolve.
Benefits:
- Industry-Leading pre-built models: Azure has fantastic, out-of-the-box models for invoices, receipts, health insurance cards, W-2s, and ID documents.
- Custom neural document models: The UI for labeling and training your own custom extraction models is highly polished and requires relatively few samples to get good results.
- Handwriting: Exceptional handling of messy handwriting and cursive.
Negative points :
- Ecosystem lock-in: The best features often require deep integration into Azure Cognitive Services or Power Automate.
- Cost of custom models: Running custom neural models can become expensive at a high volume.
Google Document AI

Google dominates ecosystem integration and multi-column layout parsing. The engine itself is powerful, but development teams frequently sacrifice weeks navigating its steep learning curve just to orchestrate basic workflow automation. The complexity often outweighs the benefits for straightforward extraction tasks.
Benefits :
- Specialized parsers: Offers an extensive library of specialized parsers (e.g., mortgage documents, procurement, utility bills) trained on massive datasets.
- Human-in-the-Loop (HITL): Built-in tools for human review to handle low-confidence extractions, which is crucial for compliance-heavy industries.
- Advanced layout parsing: Exceptionally good at understanding reading order, paragraphs, and complex layouts using Google's deep OCR heritage.
Negative points :
- Complexity: Can be overly complex to set up. You have to manage processors, processor versions, and GCP IAM permissions, which has a steeper learning curve.
- Pricing : Costs vary wildly depending on whether you use a basic OCR processor, a specialized parser, or a custom-trained model.
LLM-based solutions (Claude, Gemini, ChatGPT... )
Vision-language models offer novel semantic output, allowing you to query specific fields as if you were talking to a human. Nevertheless, these systems exhibit high average latency and hallucinate frequently at scale. For compliance-heavy finance workflows, injecting unpredictable hallucinations introduces an unacceptable level of risk.
Benefits :
- Contextual mastery: LLMs can understand the meaning of the text. They can identify a "termination clause" even if it's worded differently in 100 different contracts.
- Zero-shot extraction: You don't need to train a model. You can simply prompt: "Extract the vendor name, total amount, and line items, and return it as JSON
- Massive context windows: Models like Gemini 1.5 Pro can ingest entire 1,000-page PDFs at once and extract data spanning across multiple pages.
Negative points :
- Hallucinations: LLMs can occasionally "guess" or make up data if a field is illegible or missing, whereas traditional OCR tools simply leave it blank.
- Lack of spatial awareness: LLMs are generally poor at returning exact pixel coordinates (bounding boxes) for where the text was found on the page.
- Unpredictable costs/Latency: Processing heavy images through an LLM can be slower than traditional OCR, and token-based pricing makes it hard to estimate exactly what a single page will cost.
You can check an up-to-date benchmark leaderboard about LLM models.
Specialized AI platforms
Dedicated IDP (Intelligent Document Processing) platforms prioritize the developer experience. Mindee, for example, provides developer-friendly APIs to automatically extract structured data from unstructured documents. They outpace generic cloud APIs by offering off-the-shelf AI models for common documents—like invoices, receipts, and passports—alongside a custom API builder to train bespoke models for company-specific documents.
Benefits:
- Superior developer experience (DX): They offer beautiful documentation, robust SDKs (Python, Node, Go, etc.), easy webhook integrations, and self-serve API keys. You can usually get a proof-of-concept running in minutes.
- The "Smart abstraction" Layer: Many of these platforms actually use Azure, AWS, or LLMs under the hood. They act as an orchestration layer, routing your document to the best underlying engine automatically and unifying the output format so you don't have to manage multiple ML pipelines.
- Built-in UI for validation: Platforms like Rossum and Mindee provide out-of-the-box, embeddable user interfaces. If the AI is unsure about a field, it queues the document in a slick UI for a human operator to click and correct, automatically feeding that data back to fine-tune the model.
Negative points:
- The "Convenience premium": Because you are paying for a highly polished orchestration and UI layer on top of the base compute, the per-document cost can be significantly higher than hitting raw AWS or Azure APIs directly.
- Black box risk: Since the platform handles the routing, you have less granular control over how the data is being extracted. If an underlying model changes and affects your results, you are reliant on the IDP vendor to fix it.
- Overkill for simple pipelines: If you just need a quick-and-dirty OCR script to dump text into a database, a heavy IDP platform introduces unnecessary bloat.
{{cta-consideration-1="/in-progress/global-blog-elements"}}
Establish benchmarking and evaluation criteria
Real-world line-item extraction reliability and average latency dictate your operational ROI, rendering raw OCR accuracy a useless vanity metric.
Evaluating an IDP models benchmark requires testing against reality. Amazon Textract forces engineers to navigate a fragmented ecosystem of specific endpoints.
You might call detect document text for raw text, analyze expense for receipts, analyze id for passports, or analyze lending for mortgage packages. This fragmentation shifts the heavy lifting onto your developers.
Instead, evaluate your alternatives based on geometric precision and field reliability. Production-ready APIs provide immediate, structured payloads. Mindee does not just return extracted text; it provides the exact X/Y geometric coordinates (Polygons / Bounding Boxes) of where that text lives on the page. This geometric data is critical for building user interfaces where an auditor can click a piece of data and see exactly where it originated.
.webp)
Furthermore, demand granular confidence scores. Your API must provide a reliability rating (e.g., Low, High, Certain) indicating how certain the AI is about an extracted field. This enables developers to push data to databases automatically when certainty is high, while routing confusing documents to a human reviewer safely.
.webp)
Calculate cost and performance considerations
Configuration expenses, ongoing maintenance, and custom integration development routinely eclipse advertised pay-per-page pricing. Massive cloud providers appear inexpensive when analyzing the raw API cost per 1,000 pages, but that calculation ignores the engineering salaries consumed by writing boilerplate HTTP code.
The analyze expense api and similar generic tools struggle profoundly with line-item accuracy in nested tables. If the engine fails on multi-column layouts, your team will waste days writing regular expressions to correct the output. You need predictable pricing models and strong tooling to offset these risks.
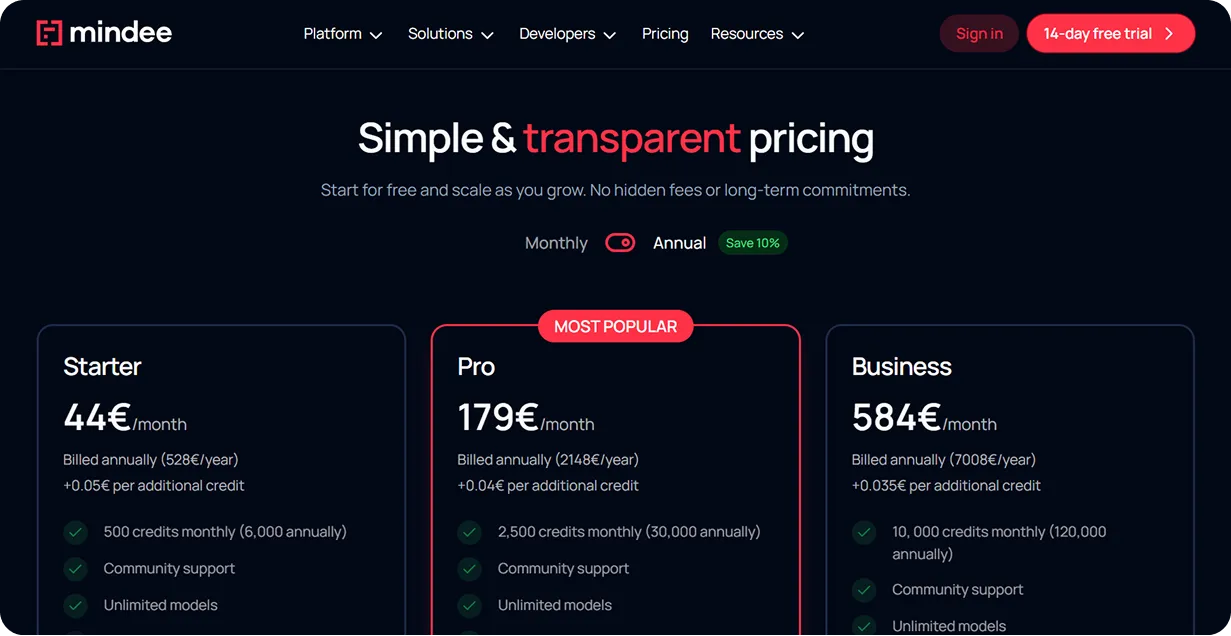
Usage-based data processing charges spiral uncontrollably during volume spikes. Predictable subscription models guarantee stability. Mindee utilizes a credit system where 1 credit equals 1 page processed. The Starter tier provides 500 credits for €44 per month, while the Pro tier bumps you up to 2,500 credits for €179 per month. The Business tier scales to 10,000 credits for €584 per month, and custom Enterprise pricing supports massive volumes exceeding 250,000 credits annually.
You can also dramatically reduce costs by utilizing official SDKs (Client Libraries). Mindee provides officially supported, open-source libraries in Python, Node.js, Java, .NET (C#), Ruby, and PHP. These deliver type safety, built-in error handling, and code autocompletion, effectively eliminating the need to write custom REST API wrappers.
Design integration and workflow flexibility
A powerful extraction engine fails completely if it cannot integrate seamlessly with your existing tech stack and execute conditional routing logic. Amazon Augmented AI (A2I) offers human review frameworks but aggressively locks you into AWS. Modern document processing pipelines demand integration flexibility.
Documents rarely arrive perfectly formatted, requiring intelligent pre-processing before extraction even begins.
You can use tools like Mindee's Split to handle multi-page files by automatically detecting where individual documents begin and end. Next, Classify acts as an intelligent routing engine, categorizing incoming files so they trigger the correct extraction pipeline. For collated images—like three receipts photographed together on a desk—Crop detects distinct documents, isolates them, and generates separate files to ensure data isn't mixed up.
.webp)
Once the data is extracted, Seamless app integrations allow your team to move fast. Operations teams without dedicated engineering resources can integrate directly with No-Code platforms like Zapier, N8N, and Make (formerly Integromat). For heavy workloads, Webhooks actively push the JSON results back to your system once the AI finishes. If you need absolute control, you can interact directly with the RESTful API via standard HTTP POST requests.
Leverage model customization and AI capabilities
Legacy template-oriented systems break the moment a vendor alters a logo or shifts a margin. Modern extraction platforms utilize advanced language models and continuous learning to adapt dynamically, eliminating the need for rigid coordinate mapping.
The most profound advancement in AI capabilities is RAG (Continuous Learning) integration.
Instead of fully retraining an AI model when it fails on a novel layout, you correct the error once. The system remembers this correction and instantly applies it to similar documents in the future, getting smarter on the fly. You can also deploy custom validation layers easily. You can extract your data automatically by creating a custom extraction model on Mindee. Upload an invoice example and the system turns it into a structured JSON format instantly.
For international organizations, data processing localization is a critical capability. To comply with strict privacy laws like GDPR, higher tiers allow you to force Mindee to process your documents exclusively in specific geographic regions (e.g., only in Europe) and enforce strict retention policies so your data is never stored.
{{cta-consideration-1="/in-progress/global-blog-elements"}}
Apply extraction to industry use cases
Specialized extraction APIs transform industry-specific bottlenecks into highly automated, predictable pipelines. Abstract technical features possess value only when applied to business outcomes, and the limitations of basic text detection become obvious in high-stakes environments.
Invoice processing for accounts payable requires flawless line-item extraction across infinite vendor variations. An IDP solution must capture totals, tax rates, and individual product lines reliably. Automating this data entry accelerates month-end reconciliation and eliminates vendor payment delays. In financial services and logistics, speed and accuracy dictate success when processing bills of lading, customs declarations, or assessing lending risk. A single omitted digit on a commercial invoice will halt international shipping operations. Similarly, claims document processing in the insurance sector requires parsing wildly unstructured data, ranging from handwritten incident reports to complex medical bills. Specialized IDP platforms handle these variations by applying semantic understanding instead of brittle rules.
Align your extraction strategy with business goals
The optimal Textract alternative minimizes your engineering overhead while maximizing data accuracy across your operations. Raw OCR is a solved problem. The current challenge requires turning unpredictable document pixels into clean, reliable JSON that your database trusts implicitly. Before signing a massive enterprise cloud contract, test your most chaotic unstructured documents against a developer-friendly API. Evaluate the extraction speed, review the confidence scores, and measure the integration effort. The difference between a fragile pipeline and a robust automation system lies entirely in your tooling selection.
About
.svg)

.webp)
.webp)
