
.webp)
API DEV-First
4.8/5 (30+ reviews)
API OCR pour l’extraction de texte et de données depuis vos documents
Transformez vos PDF, scans et images en JSON structuré en quelques millisecondes. Testez l’extraction OCR directement avec votre document.
Tester un document
Aucune carte bancaire requise
.webp)
Reconnu par les meilleures équipes à travers le monde

Tout ce dont vous avez besoin avec une API OCR
OCR haute précision & extraction de texte
Extrayez le texte de vos PDF, scans et images grâce à un moteur OCR conçu pour des documents réels. Idéal pour l’extraction de texte PDF via API.
Extraction de données structurées
Allez au-delà du texte brut. Extrayez automatiquement des champs structurés et récupérez un JSON propre, directement exploitable par vos systèmes.
OCR multi-documents & analyse de mise en page
Gérez tout type de documents et de mises en page complexes, avec ou sans templates. Adaptez facilement votre schéma de données.
Scores de confiance et signaux de fiabilité
Chaque champ extrait est associé à un score de confiance pour automatiser vos décisions, identifier les cas limites et éviter les vérifications manuelles.
API OCR pensée pour les développeurs
API REST simple, documentation claire, SDKs, outils no-code compatibles et tarification prévisible.Intégrez l’OCR en minutes, pas en semaines.





.webp)

Most advanced AI OCR features getting your document extraction to the next level
Our AI-driven OCR API provides high-precision data extraction for all document formats, enabling businesses to automate workflows with speed and total reliability.
Accelerate processing by automatically breaking multi-page uploads into separate documents. Our solution detects document boundaries to split batches into distinct records ready for extraction.
Automate your workflow by sorting incoming documents instantly. Mindee OCR API distinguishes between document types, routing each file to its specific category for streamlined data management.
Digitize multiple documents scanned on a single page with automated detection. Mindee OCR API isolates and crops each item into a standalone file, ensuring every record is processed individually.
Bien plus qu'une API. Ajustez, testez et personnalisez.
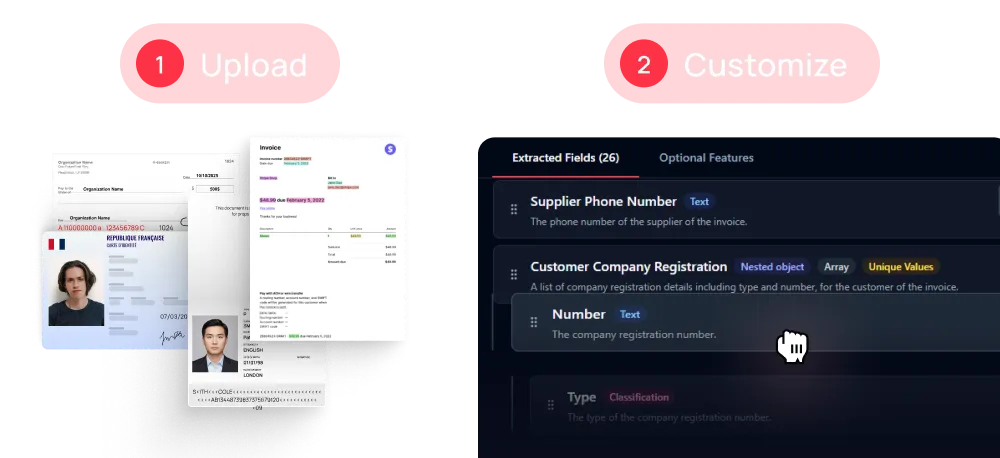
Créez votre modèle de zéro ou partez d’un modèle parmi plus de 30 disponibles dans l’interface Mindee
Créez des modèles d’extraction personnalisables grâce à des schémas de données interactifs.

Support Multilingue
Analysez vos documents dans toutes les langues.

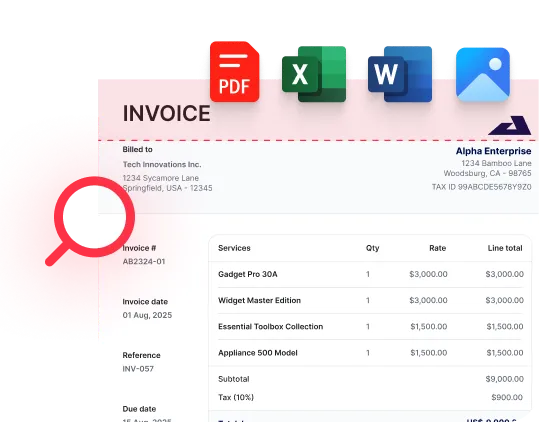
Ajoutez vos documents dans n'importe quel format
Ajoutez des fichiers .pdf, .jpg, .png, .docx, .xlsx… et bien plus encore. Aucun temps perdu en conversion.
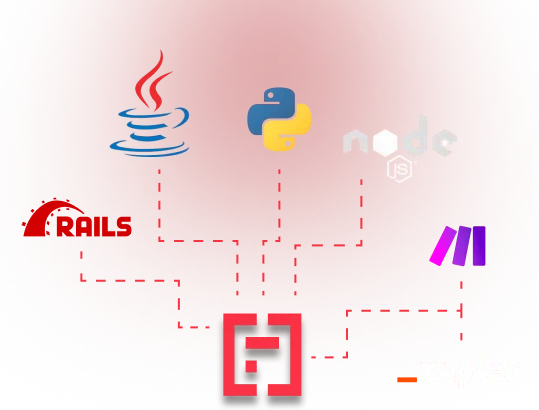
Intégrez Mindee à votre workflow en quelques clics
SDKs et outils low-code compatibles.

Vos données sont protégées
Hébergement en Europe disponible
Conforme au RGPD et au CCPA
Fonctionnalités exclusives pour utilisateurs avancés
.webp)
OPTION
Confidence scores
Gardez le contrôle sur le travail de l’IA grâce aux labels de confiance.
OPTION
Polygons
Mettez en évidence vos variables pour une meilleure compréhension, avant et après l’extraction.
OPTION
RAG
Créez votre propre bibliothèque de documents pour enrichir votre modèle et gérer les cas limites.

FAQ pour en savoir plus sur l'API
Puis-je combiner des API d'OCR et des LLM pour améliorer le traitement des documents ?
Absolument. De nombreuses entreprises utilisent des architectures hybrides : les API OCR gèrent la couche d'extraction structurée, fournissant des données propres au niveau du champ, tandis que les LLM ajoutent un raisonnement, un enrichissement ou une synthèse par la suite. Cette approche offre une rentabilité, une précision et des fonctionnalités d'IA avancées là où elle apporte le plus de valeur ajoutée.
Are LLMs more expensive than OCR APIs for high-volume document processing?
Yes — in most high-volume use cases, LLMs are significantly more expensive than OCR APIs. LLM pricing is based on tokens, which makes processing large or multi-page documents costly. OCR APIs like Mindee offer flat, predictable per-document pricing that scales much more affordably for structured extraction tasks.
Quelle est la différence entre l'API OCR et le LLM pour l'extraction de documents ?
Une API OCR est conçue pour extraire des champs de données structurés (tels que les numéros de facture, les dates, les montants) des documents commerciaux avec une grande précision et des résultats prévisibles.
Un modèle de langage large (LLM) tel que GPT-4 peut gérer des raisonnements plus complexes et du texte non structuré, mais peut halluciner les données et entraîner des coûts plus élevés pour les tâches d'extraction. Les API OCR sont généralement mieux adaptées aux documents structurés volumineux, tandis que les LLM sont utiles pour la synthèse, l'analyse de texte libre et le raisonnement.
Quelle est la meilleure façon de compresser des PDF pour l'OCR ?
La meilleure méthode consiste à appliquer une compression sans perte après la numérisation, mais avant d'envoyer le document à votre API d'OCR. Cela préserve la clarté de l'image et la lisibilité du texte.
