
.webp)
API DEV-First
4.8/5 (30+ avis)
OCR de factures, de reçus & API d' extraction de données de documents
Analysez le texte et les données structurées de factures, reçus et de tout autre document. Obtenez un JSON propre et fiable en quelques millisecondes — prêt pour l'automatisation de vos processus.
Testez un document
Aucune carte bancaire requise
.webp)
Les meilleures équipes du monde entier nous font confiance

Tout ce dont vous avez besoin avec pour une API OCR prête à l'emploi
OCR de factures et extraction de texte
Obtenez automatiquement les numéros de facture, les dates, les postes, les totaux, les taxes, les fournisseurs et les adresses des PDF et des factures numérisées. Conçu pour de vraies factures — avec une précision pensée pour le monde réel.
OCR de reçus pour les notes de frais
Retrouvez le nom du commerçant, la date de transaction, la devise, les totaux, la TVA et les postes des reçus, photos et scans mobiles. Gérez les reçus désordonnés du monde réel à grande échelle.
Extraction de données structurées de documents
Allez au-delà du texte brut. Recevez automatiquement des champs structurés et recevez un JSON propre et utilisable, prêt pour traiter vos factures ou reçus.
OCR multi-documents et prenant en compte la mise en page
Traitez les factures, reçus, formulaires, contrats et lots de documents mixtes — avec ou sans modèles. Adaptez votre schéma de données à votre cas d'usage.
Scores de confiance et signaux de fiabilité
Chaque champ extrait est accompagné d'un score de confiance, vous permettant d'automatiser le processus de validation.






Les fonctionnalités OCR IA les plus avancées pour faire passer votre extraction de documents au niveau supérieur
Notre API OCR basée sur l'IA offre une extraction de données de haute précision pour tous les formats de documents, permettant aux entreprises d'automatiser leurs flux de travail avec rapidité et une fiabilité totale.
Accélérez le traitement en divisant automatiquement les téléchargements de plusieurs pages en documents distincts. Notre solution détecte les limites des documents pour diviser les lots en enregistrements distincts prêts pour l'extraction.
Automatisez votre flux de travail en triant instantanément les documents entrants. L'API OCR de Mindee distingue les types de documents, acheminant chaque fichier vers sa catégorie spécifique pour une gestion des données simplifiée.
Numérisez plusieurs documents scannés sur une seule page avec détection automatique. L'API OCR de Mindee isole et recadre chaque élément dans un fichier autonome, garantissant que chaque enregistrement est traité individuellement.
Plus qu'une simple API. Affinez, testez et personnalisez.
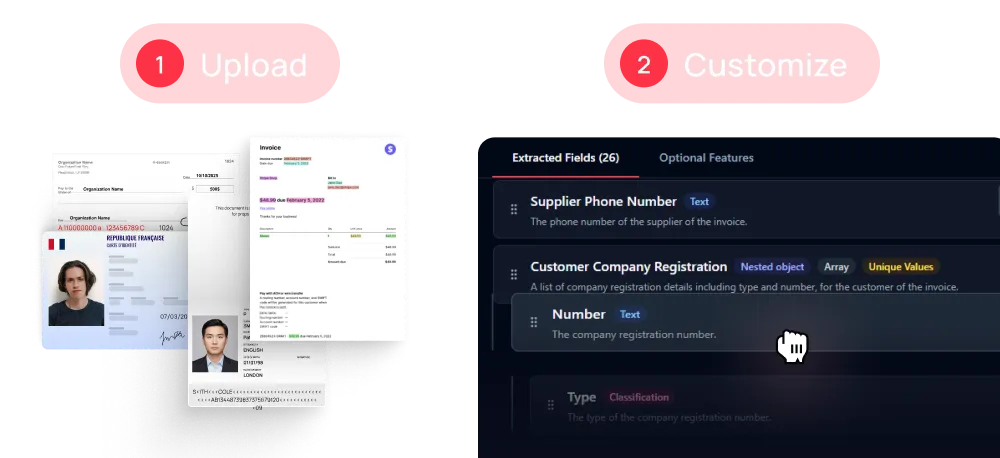
Personnalisez votre modèle en partant de zéro ou démarrez avec l'un des plus de 30 modèles disponibles sur l'interface Mindee.
Créez des modèles d'extraction personnalisables avec des schémas de données interactifs.

Support multilingue
Analysez vos documents dans toutes les langues.

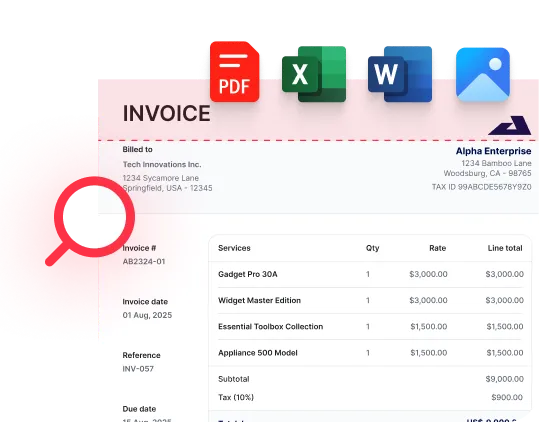
Téléchargez des documents dans tous les formats
Ajoutez des fichiers .pdf, .jpg, .png, .docx, .xlsx, ... et plus encore. Aucun temps de conversion nécessaire.
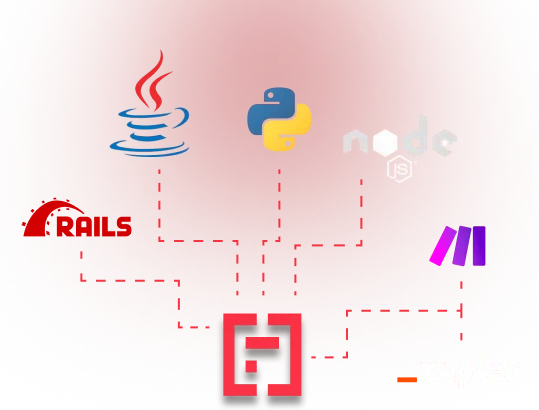
Intégrez Mindee à votre workflow en quelques minutes
SDK et outils low-code pris en charge.

Vos données sont protégées
Hébergement en UE disponible
Conforme au RGPD et au CCPA
Fonctionnalités exclusives de Mindee pour les utilisateurs avancés
.webp)
Feature
Scores de confiance
Faites confiance à la donnée extraite grâce à notre indicateur de fiabilité.
Feature
Polygones
Visualisez exactement d'où provient chaque donnée extraite dans votre document.
Feature
RAG
Créez votre propre bibliothèque de documents pour enrichir votre modèle et gérer les cas particuliers.

FAQ sur l'API OCR de Mindee
Une API d'extraction de documents de données est-elle identique à une API de web scraping ?
Non. Bien que les deux « extraient des données », la technologie sous-jacente est très différente.
- API de grattage Web : Conçu pour naviguer dans les structures DOM, contourner les CAPTCHA et collecter des données à partir de HTML/CSS. Ils recherchent les bonnes informations avant d'extraire quoi que ce soit.
- API d'extraction de données (Document AI) : Spécialement conçu pour traiter les « fichiers visuels non structurés » tels que les PDF, les images numérisées et les e-mails. Ils ne recherchent pas de <div>balises ; ils utilisent l'OCR et la vision spatiale pour comprendre la mise en page d'une page physique
Puis-je extraire des tableaux complexes à partir de PDF numérisés avec Mindee ?
Oui, avec Mindee, vous pouvez tester cette fonctionnalité lors de votre essai gratuit sur notre plateforme en ajoutant un exemple de document à traiter. La reconnaissance des rubriques et des tableaux complexes sera entièrement prise en charge à partir de PDF ou de tout autre format d'image.
C'est là que les API généralistes échouent souvent. L'OCR standard peut vous donner une « soupe de mots ».
Pour les tableaux complexes (lignes multilignes, cellules fusionnées ou en-têtes imbriqués), vous avez besoin d'un outil conscient du contexte et des espaces.
Astuce de pro: Les LLM généralistes hallucinent souvent sur les structures types tableaux, rubriques à plusieurs colonnes. Pour les documents financiers « compliqués », recherchez des solutions OCR qui utilisent des modèles de vision spécifiques plutôt que de simples modèles texte-to-JSON génériques
Comment extraire des PDF ou des documents longs de plus de 10 Mo ?
Avec Mindee, vous pouvez ajouter des documents allant jusqu'à 100 Mo et jusqu'à 200 pages.
Les fichiers volumineux (par exemple, un dossier emprunteur de 100 pages) ne doivent jamais être traités dans une boucle « synchrone ». Privilégier plutôt une de ces deux méthodes d'API :
- Traitement asynchrone (Pooling) : Vous soumettez le fichier, vous recevez un job_id et l'API le traite en arrière-plan.
- Webhooks : Une fois terminée, l'API « envoie un ping » à votre serveur avec le JSON structuré. Il s'agit de la référence absolue pour toute configuration d'API d'extraction de données automatisée pour chaque langage (Python, Node JS, Java, etc.)
Quelle est la précision des tableaux et des rubriques complexes selon les différentes mises en page ?
Mindee pourrait être la solution idéale pour vous si vous avez besoin d'une solution OCR fiable, pour extraire les données de tableaux et rubriques similaires, avec une précision élevée.
La précision varie considérablement en fonction de la mise en page. Bien que les « paires clé-valeur » (comme le montant total ou la date) soient faciles, les rubriques (description, quantité, prix unitaire) sont les plus difficiles à analyser car chaque fournisseur utilise un style de tableau différent.
Conseil de référence : Ne vous fiez pas à l'affirmation marketing d'une « précision de 99 % ». Testez le même ensemble de 50 factures « compliquées » auprès de fournisseurs pour voir qui oublie des articles ou qui confond la « quantité » avec le « taux d'imposition ».
Comment puis-je garantir la validité du format structuré JSON ?
L'obtention du JSON est la première étape ; l'obtention d'un JSON valide est la deuxième étape. La plupart des API modernes, comme Mindee, vous permettent de définir un schéma de données. Pour vous assurer que votre base de données ne tombe pas en panne :
- Utiliser Pydantique (Python) ou Zod (TypeScript) pour valider la sortie de l'API.
- Si l'extraction ne correspond pas au schéma (par exemple, un invoice_id obligatoire manquant), signalez-la pour qu'elle soit examinée par un humain.
Qu'en est-il de l'extraction de données à partir d'écritures manuscrites ou de documents multilingues ?
Mindee soutient tous les alphabets, toutes les langues, toutes les écritures manuscrites documents lisibles par l'homme.
La plupart des API de premier plan prennent désormais en charge l'écriture manuscrite et plus de 100 langues. Cependant, attendez-vous à une baisse de confiance de 15 à 20 % pour l'écriture cursive par rapport au texte imprimé. Pour les langues de niche, vérifiez si le moteur d'OCR prend en charge le jeu de caractères spécifique (par exemple, le cyrillique ou l'arabe).
Quels sont des exemples concrets de classification automatique de documents ?
En identifiant le type de document au point d'entrée, les organisations peuvent automatiser le routage des fichiers vers les flux de travail appropriés sans une seule seconde de triage manuel.
Voici quelques-unes des les exemples les plus percutants du monde réel de classification automatique des documents :
Dans le comptes créditeurs département, la classification change la donne pour les départements qui reçoivent d'énormes pièces jointes PDF en masse de la part des fournisseurs. L'API peut instantanément faire la distinction entre une facture, une note de crédit et un relevé mensuel. Cela garantit qu'une note de crédit n'est pas traitée par erreur comme une facture, évitant ainsi des erreurs de paiement coûteuses et rationalisant l'ensemble du cycle financier.
Il est tout aussi essentiel pour correspondance bidirectionnelle et flux de travail de réconciliation. Souvent, un seul scan peut regrouper un bon de commande avec le bon de livraison correspondant. La classification automatique identifie la limite et le type spécifique de ces deux enregistrements distincts, ce qui permet de les croiser automatiquement à des fins d'audit. En les classant d'abord, le système sait exactement quel moteur d'extraction utiliser pour le bon de commande par rapport au bon de livraison.
Pour intégration des clients, cette technologie crée une expérience utilisateur fluide. Un nouveau client peut télécharger un seul « dossier d'intégration » contenant sa carte d'identité, une facture de services publics comme preuve de domicile et un contrat signé. Le moteur de classification reconnaît chaque élément du paquet et les achemine vers des modèles d'extraction spécialisés, tels qu'une API de passeport ou une API de facture de services publics, pour une vérification instantanée et automatique.
De même, dans gestion de flotte de véhicules, la classification automatisée permet la numérisation fluide de dossiers de maintenance complexes. Les certificats d'assurance, les carnets de bord des véhicules et les factures de réparation sont souvent scannés en un seul lot. La logique de classification garantit que chaque document est correctement identifié et classé dans le bon actif du véhicule, ce qui permet aux gestionnaires de flotte de suivre l'historique de conformité et de maintenance sans aucun tri ou classement manuel.
Vous pouvez consulter d'autres exemples concrets de la manière dont les entreprises tirent parti de cette technologie en visitant témoignages de clients.
L'API OCR de Mindee est-elle gratuite ?
Nous proposons un essai gratuit de 14 jours afin que vous puissiez tester pleinement nos différents API OCR, aucune carte de crédit n'est requise. Ensuite, nous proposons différents niveaux de tarification en fonction du volume de pages traitées et des fonctionnalités dont vous pourriez avoir besoin. Consultez la page de tarification pour plus de détails sur les bons de commande.
