
.svg)


Table of Contents
In the world of large language models (LLMs), efficient data processing is a must. One of the key techniques used to manage large or complex datasets is chunking — the practice of breaking down information into smaller, manageable units called chunks. Chunking helps maintain performance, preserve context, and reduce computational costs, all while enhancing the model's ability to understand and generate accurate outputs.
What Is LLM Chunking?
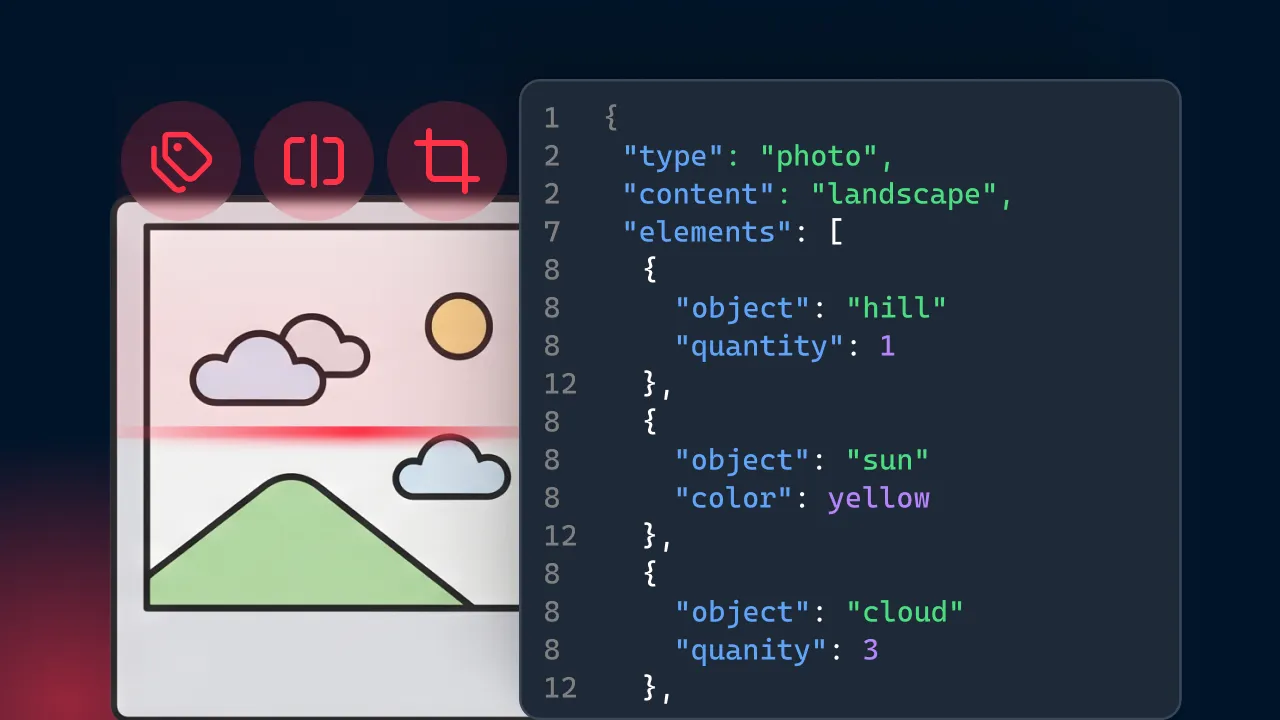
Chunking refers to the segmentation of data into digestible pieces that can be processed independently by a language model. It's similar to how humans learn and remember better when information is grouped logically. For LLMs, this segmentation prevents overload, preserves context, and improves efficiency.
Why Chunking Matters
- Efficient processing: Smaller data units are easier and faster to analyze.
- Context preservation: Maintaining local context within chunks improves coherence and accuracy.
- Resource optimization: Reduces memory usage and speeds up computation.
- Scalability: Enables handling of growing datasets or longer documents without loss in performance.
Common Chunking Strategies for LLMs
1. Context-Aware Chunking
This strategy involves breaking data at points where the meaning remains intact. It ensures that each chunk has sufficient context for the model to interpret the information accurately.
2. RAG Chunking (Retrieval-Augmented Generation)
RAG integrates external information into the model's context by retrieving relevant chunks from a knowledge base.
3. Vector-Based Chunking
Here, chunks are transformed into vector embeddings for efficient indexing and retrieval.
How to Implement Chunking in Your Pipeline
Step 1: Identify the Data Type
- Textual: Requires preserving narrative flow and context.
- Numerical/Structured: Focus on logical divisions (e.g., table rows, records).
Step 2: Choose Your Strategy
Evaluate based on:
- Need for external data (use RAG)
- Length of input/output (consider vector chunking)
- Importance of nuance/context (use context-aware)
Step 3: Break Down the Data
- Establish logical breakpoints (e.g., paragraph boundaries, topic shifts).
- Ensure each chunk is self-contained.
Step 4: Process in Chunks
- Use parallel processing to speed up analysis.
- For vector/RAG: fetch and augment context as needed.
Step 5: Reassemble and Interpret
- Combine results while maintaining the original context.
- Validate outputs against the source to ensure integrity.
Real-World Applications of Chunking
Tips for Optimizing Chunking
- Chunk size matters: Too small loses context, too large adds overhead. Test and tune.
- Overlap chunks if needed: Especially for generative tasks, overlap helps preserve meaning.
- Monitor performance: Track latency, output quality, and memory usage to fine-tune your strategy.
Challenges to Watch Out For
- Losing context: Breaks at the wrong point can distort meaning.
- Over-reliance on retrieval: In RAG, poor retrieval leads to poor outputs.
- Implementation complexity: Balancing preprocessing, chunking, and postprocessing needs careful orchestration.
Conclusion: Unlocking the Full Potential of LLMs
Chunking is not just a technical hack—it's a foundational method for making LLMs practical at scale. Whether you're analyzing long reports, powering search engines, or building generative applications, choosing the right chunking approach can make all the difference.
By combining thoughtful segmentation with strategies like RAG and vectorization, developers can boost performance, reduce costs, and build AI systems that scale and adapt to real-world data complexities.
About
.svg)

.webp)
.webp)
.webp)